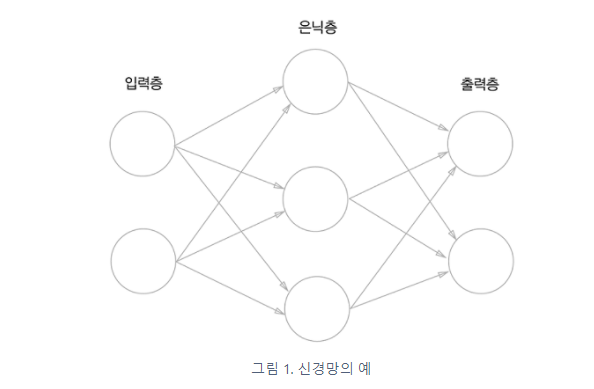
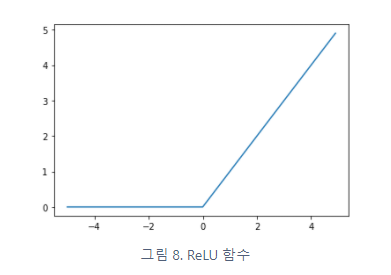
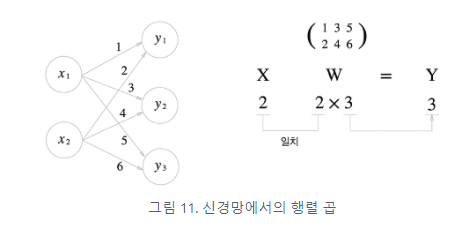
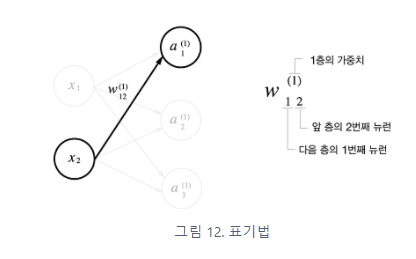
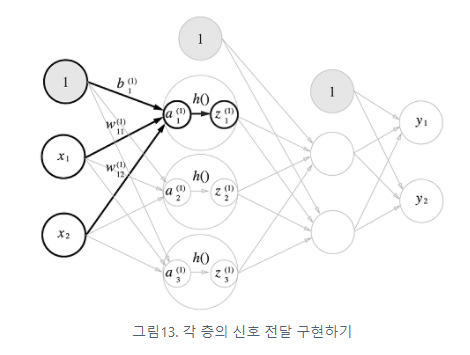
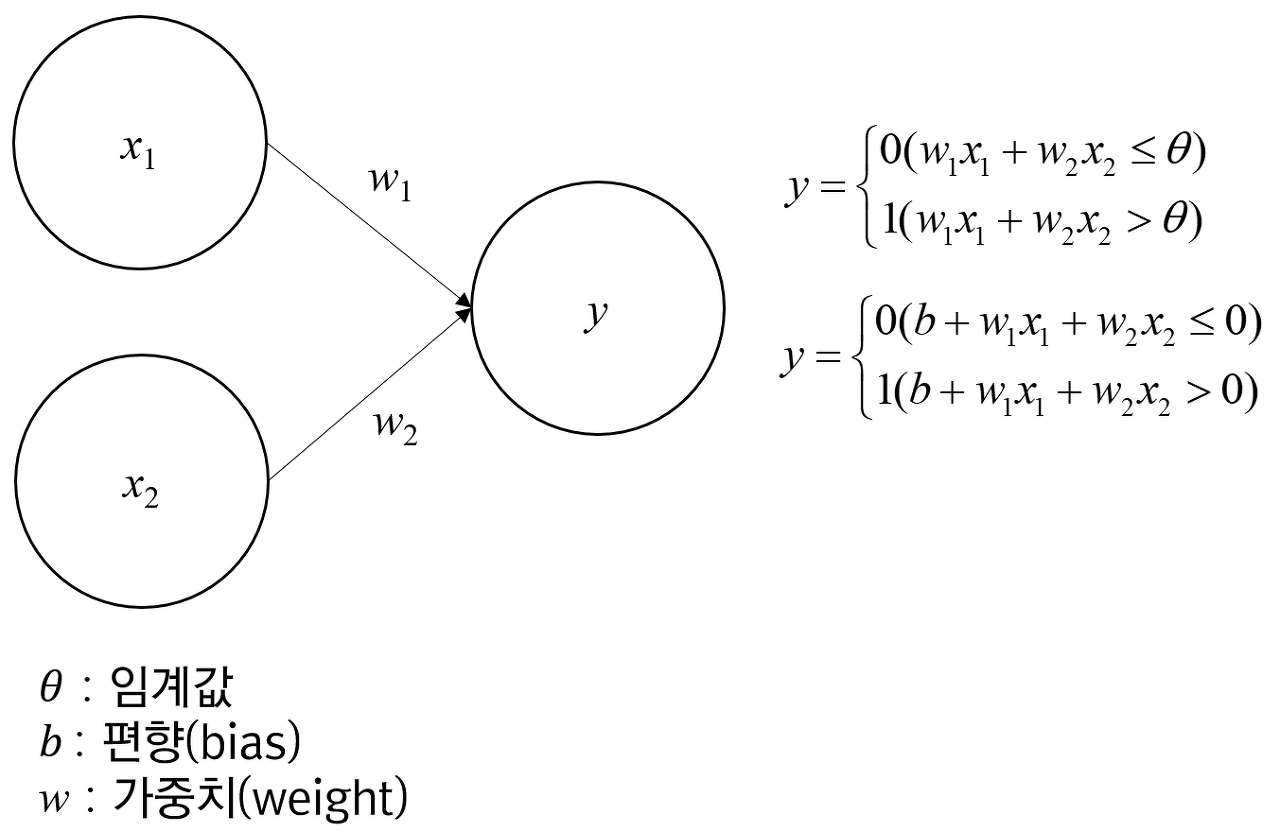
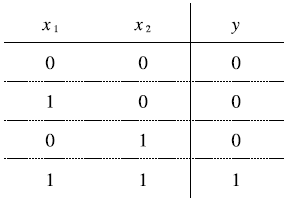
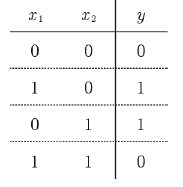
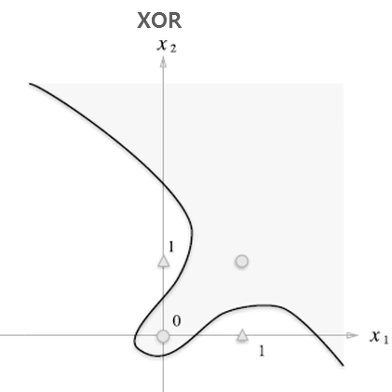
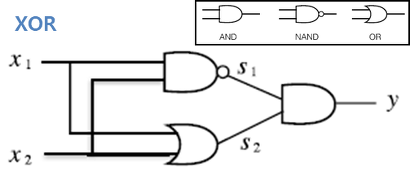
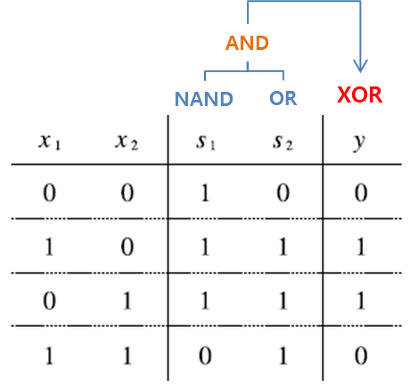
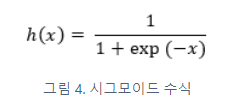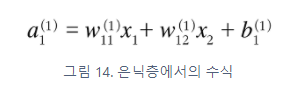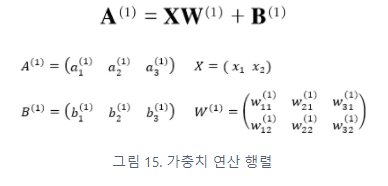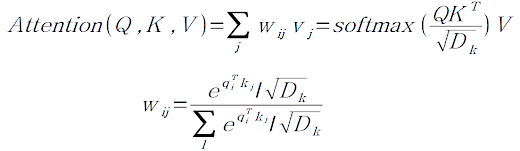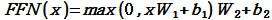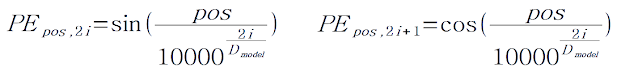위의 그림 속 신경망은 3층으로 구성되어있지만 가중치를 갖는 층이 2개이기 때문에 2층 신경망 이라고 한다.
y=0 (b+w1x1+w2x2<=0) y=1 (b+w1x1+w2x2>0)
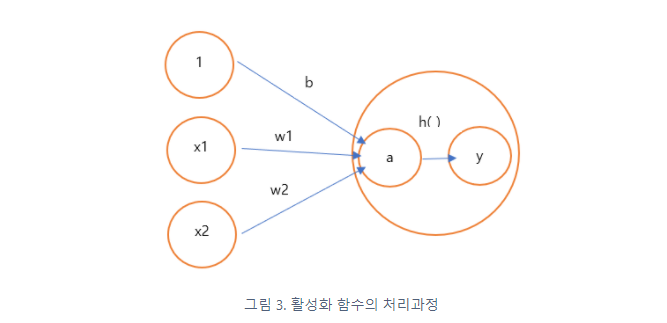
편향(bias)은 하나의 뉴런으로 입력된 모든 값을 다 더한 다음에(가중합이라고 합니다) 이 값에 더 해주는 상수입니다. 이 값은 하나의 뉴런에서 활성화 함수를 거쳐 최종적으로 출력되는 값을 조절하는 역할을 함
활성화 함수(activateion function) : 입력 신호의 총합을 출력 신호로 변환하는 함수. 변환된 신호를 다음 뉴런에 전달한다. 입력 신호의 총합이 활성화를 일으키는지를 정하는 역할을 한다.
a = b+w1x1+w2x2 #가중치가 달린 입력 신호와 편향의 총합 y=h(a) #a를 함수 h()에 넣어 y를 출력
3-2 활성화함수
시그모이드 함수 (sigmoid function)
신경망에서는 활성화 함수로 시그모이드 함수를 이용하여 신호를 변환하고 그 변환된 신호를 다음 뉴런에 전달한다.
시그모이드 함수 구현하기 브로드캐스트 기능: 넘파이 배열과 스칼라값의 연산을 넘파이 배열의 원소 각각과 스칼라값의 연산으로 바꿔 수행한다.
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
#브로드캐스트
#넘파이 배열과 스칼라값의 연산을 넘파이 배열의 원소 각각과 스칼라값의 연산으로 바꿔 수행
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
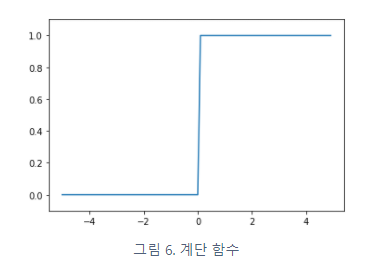
계단함수 (step function)
def step_function(x):
return np.array(x>0, dtype=np.int)
##numpy 배열을 인수로 넣을 수 있게 하는 방법
#x = np.array([-1.0, 1.0, 2.0])
#y = x>0
#y를 출력하면 0보다 큰 x값은 True로, 0보다 작거나 같은 값은 False로 나온다.
#booleaan값을 int형으로 변환시키면 True는 0, False는 1이다.
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
요즘 최근 vision 모델에서 사용하는 Transformer 모델을 공부하기전에 transformer를 공부하기위해 정리한다. ( 물론 자연어쪽도 나름 공부하기 위해서 정리를 시작하려고 한다 내가 보기 위함)
1. Transformer
트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델입니다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 성능도 RNN보다 우수하다는 특징을 갖고있습니다.
2. 트랜스포머(Transformer)의 주요 하이퍼파라미터
시작에 앞서 트랜스포머의 하이퍼파라미터를 정의합니다. 각 하이퍼파라미터의 의미에 대해서는 뒤에서 설명하기로하고, 여기서는 트랜스포머에는 이러한 하이퍼파라미터가 존재한다는 정도로만 이해해보겠습니다. 아래에서 정의하는 수치는 트랜스포머를 제안한 논문에서 사용한 수치로 하이퍼파라미터는 사용자가 모델 설계시 임의로 변경할 수 있는 값들입니다.
dmodel= 512 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미합니다. 임베딩 벡터의 차원 또한dmodel이며, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지합니다. 논문에서는 512입니다.
num_layers= 6 트랜스포머에서 하나의 인코더와 디코더를 층으로 생각하였을 때, 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미합니다. 논문에서는 인코더와 디코더를 각각 총 6개 쌓았습니다.
num_heads= 8 트랜스포머에서는 어텐션을 사용할 때, 1번 하는 것 보다 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 택했습니다. 이때 이 병렬의 개수를 의미합니다.
dff= 2048 트랜스포머 내부에는 피드 포워드 신경망이 존재하며 해당 신경망의 은닉층의 크기를 의미합니다. 피드 포워드 신경망의 입력층과 출력층의 크기는dmodel입니다.
3. 트랜스포머(Transformer)
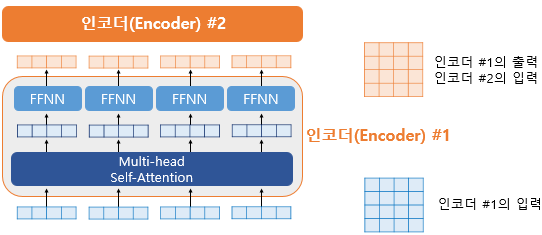
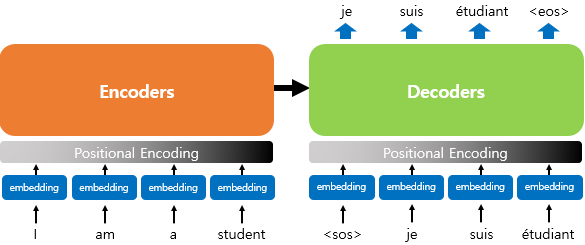
트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지하고 있습니다. 다만 다른 점은 인코더와 디코더라는 단위가 N개가 존재할 수 있다는 점입니다.
이전 seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time-step)을 가지는 구조였다면 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조입니다. 트랜스포머를 제안한 논문에서는 인코더와 디코더의 개수를 각각 6개를 사용하였습니다.
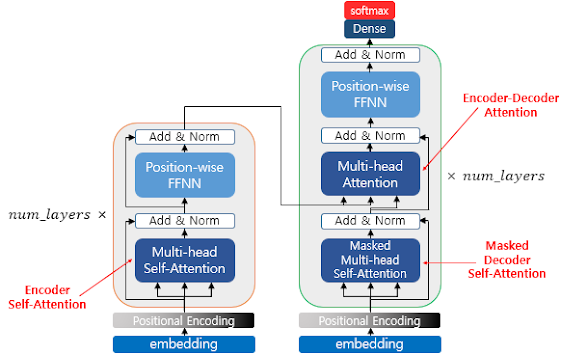
위의 그림은 인코더와 디코더가 6개씩 존재하는 트랜스포머의 구조를 보여줍니다. 이 책에서는 인코더와 디코더가 각각 여러 개 쌓여있다는 의미를 사용할 때는 알파벳 s를 뒤에 붙여 encoders, decoders라고 표현하겠습니다.
위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머 구조를 보여줍니다. 디코더는 마치 기존의 seq2seq 구조처럼 시작 심볼 <sos>를 입력으로 받아 종료 심볼 <eos>가 나올 때까지 연산을 진행합니다. 이는 RNN은 사용되지 않지만 여전히 인코더-디코더의 구조는 유지되고 있음을 보여줍니다.
트랜스포머의 내부 구조를 조금씩 확대해가는 방식으로 트랜스포머를 이해해봅시다. 우선 인코더와 디코더의 구조를 이해하기 전에 트랜스포머의 입력에 대해서 이해해보겠습니다. 트랜스포머의 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력받는 것이 아니라 임베딩 벡터에서 조정된 값을 입력받는데 이에 대해서 알아보기 위해 입력 부분을 확대해보겠습니다.
4. Transformer Architecture
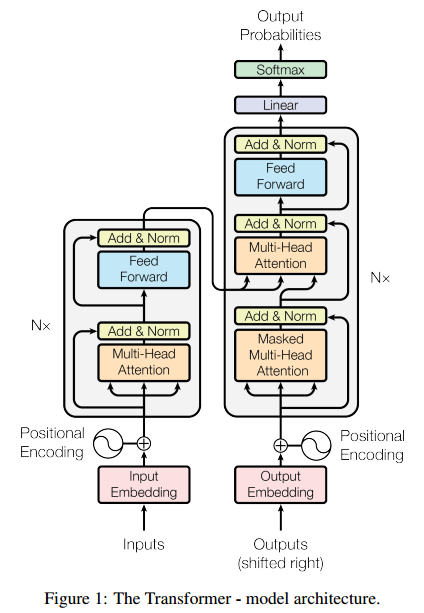
우선 논문에서 제시한 transformer의 기본 architecture는 아래와 같습니다.
위 구조가 바로 Transformer 모델의 구조입니다. Encoder-Decoder 구조를 갖는다는 것 외에는 모르는 단어가 상당히 많은데,Self-Attention, Multi-head Attention, Positional Encoding등 Transformer 모델의 구성요소와 동작원리에 대해서 알아보도록 하죠.
5. Self-Attention
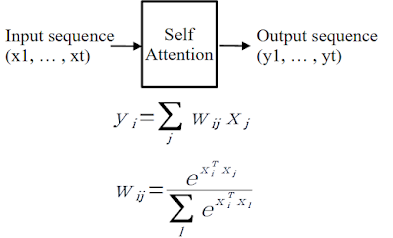
먼저Dot-product attention에 대해서 알아보자.
각 value가 key에 매칭 되어 있다고 하자.Python의 Dictionary를 떠올려도 좋습니다. ※ dict{key1 : {value1}, key2 : {value2}, ..., keyt : {value_t}}로 구성된 dictionary가 있다고 생각하자구요.
이 때weight들은query와 key의 dot-product를 0~1 사이 값으로 normalize한 값과 같다. 즉,query와 key가 비슷하면 weight가 높게,유사성이 낮으면 weight는 낮으며, 모든 weight의 합은 1이 된다.
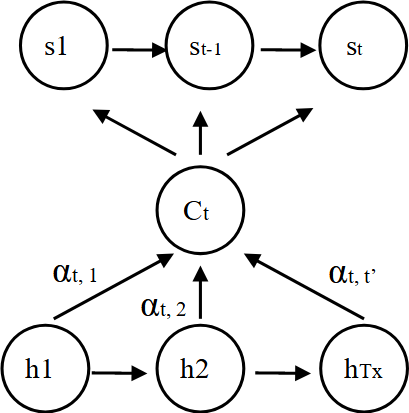
전혀 새로운 개념이 아니다. Attention 포스팅에서다룬 내용도 s를 query로 가지고 key가 h1, ..., ht였던 dot-product attention과 동일하다. 그럼self-attention은 어떤 함수일까?
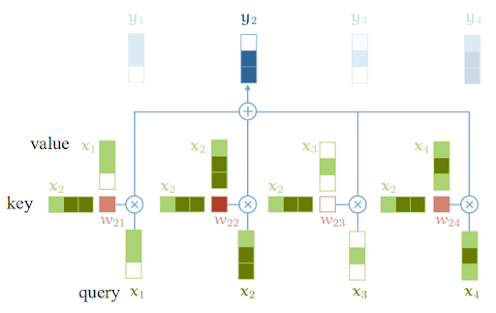
바로key와query, value가동일한 집합에 있는 것이다. 예를 들면 s_t와 s_1, ..., s_t간의 각각의 유사성을 convex sum형태로 표현한 것이다. 위 과정을 그림으로 나타내면 아래와 같다.
[출처 : Peter Bloem - Transformer]
위 예제에서 w_ij의 의미는 key x_i와 query x_j의 weight를 의미한다. 즉, y2는 x1-x2, x2-x2, x3-x2, x4-x2를 비교해 각 value들을 convex sum한 결과가 된다.
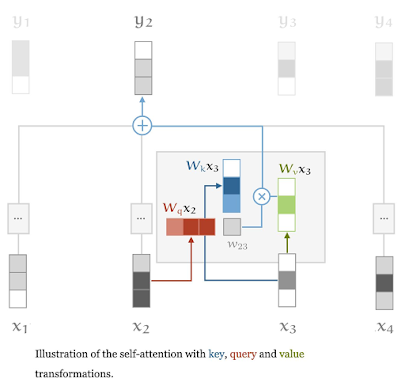
그런데 이 대로는 사실 쓸모가 없다. 왜냐하면 w_ij는 sequence(x1, ..., x4)만 있으면 자동으로 계산되는 상수나 마찬가지기 때문에다. 그래서 '학습'을 위해서 학습될 수 있는 parameter가 필요하다. (parameterize)
그래서 query, key, value에 각각 파라미터 Wq, Wk, Wv를 적용하면 위와 같이 표현할 수 있다. 이렇게 하면 학습을 통해 적절한 파라미터를 찾아서 자기 자신의 self-attention 을 학습할 수 있게 된다.
이렇게 했을 때 어떤 효과가 있을까?
위 예시는 'The', 'animal' ... 'tired' 스스로self attention한 결과이다. 예를 들면 'it'은 어떤 단어와 유사성이 가장 높았는지 self attention을 계산한 결과 it은 animal과 가장 높은 유사성을 가진 것을 알 수 있는데, 이런 효과도 대표적인 self-attention의 효과다.
6. Scaled Dot-Product Attention
Scaled Dot-Product Attention은 앞에서 배운 Dot-product attention과 거의 동일하다.
Dot-Product Attention은 기존 방법에 Key의 차원 D_k를 나눠서 scaling한 것이다. (self attention이라면 Q, K, V의 차원이 모두 같다.)
※ 논문에서는 통상 Key의 차원이 매우 높기 때문에 (예를 들어 책 한권에 나오는 모든 단어가 key가 된다.) scaling을 하지 않으면 weight vector가 잘 계산되지 않는다고 한다.
지금까지 배운 것을 한번 시뮬레이션 해보자.
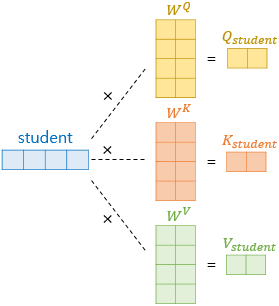
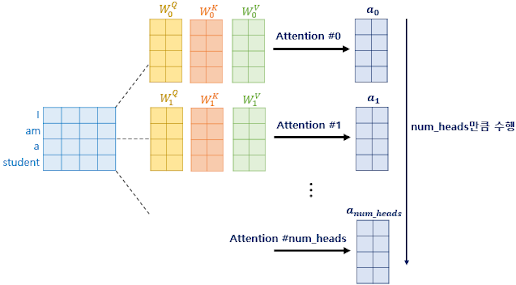
I, am, a, student라는 단어가 주어졌을 때 각각을 어떤 숫자로 vectorized 시켰다고 하자.
이 vector를 Wq, Wk, Wv로 parameterize시키면 I, am, a, student 각각의 Q, K, V 벡터를 얻을 수 있다.
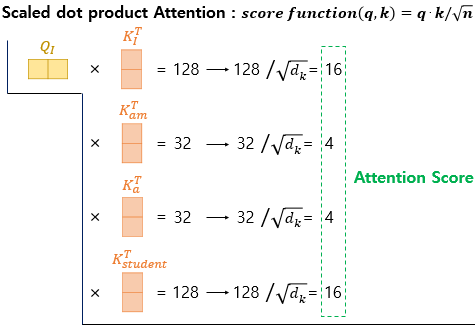
그리고 'I'의 query를 각 단어에 scaled dot product self-attention을 해보자.
'I'의 query와 'I', 'am', 'a', 'student'의 key의 dot-product를 구하고 scaling 해 주면 각 단어들간의 유사도(Attention score)가 계산된다.
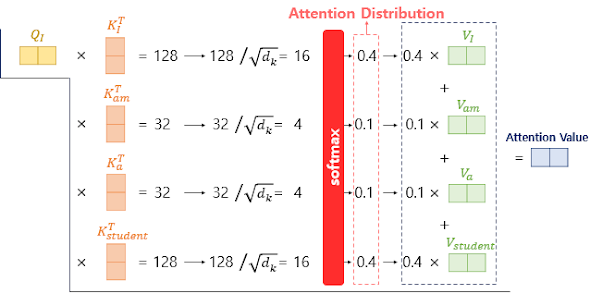
이 attention score에 softmax를 취해 합이 1인 값으로 바꿔보니 'I'는 'I'와 'student'간 유사도 높은 것을 확인할 수 있다. 이 값들을 모두 더하면 Attention value (혹은 Context vector)가 최종적으로 도출되게 된다.
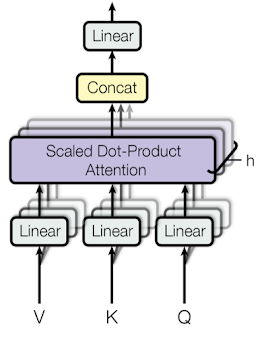
7. Multi-Head Attention
앞서 Q, K, V를 Linear transform으로 parameterized 시켜 학습할 수 있게 만들었었다. 그런데 1개씩의 파라미터로 모델이 충분한 복잡성을 못 가질 수도 있기 때문에 여러번 Linear transform 시켜줄 수 있다. 이 개념이Multi-head attention이다. ※ CNN에서 1개 이미지를 1개 필터로 Conv.하는 것이 아니라 여러개의 필터를 사용해서 많은 feature map을 뽑는 것과 동일하다.
Multi-head attention은 위에서 언급한 것 처럼학습 파라미터 수를 늘려 모델의 복잡도를 올리는 방법이고num_head는 하이퍼파라미터가 된다. (논문에서는 num_head = 8로 설정했다.)
Multi-head attention을 앞서 보여줬던 예제에 적용하면 위 그림과 같다. 동일한 과정을 num_head만큼 수행하는 것을 활인할 수 있다.
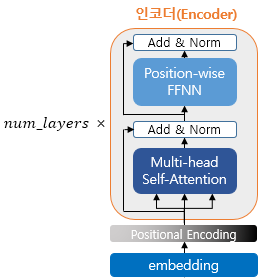
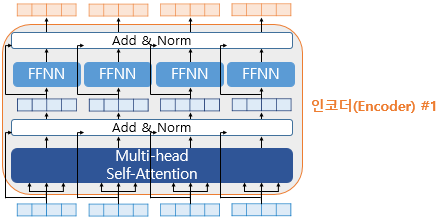
Encoder 그림의 가장 핵심인 Multi-head self-attention을 이해했다면 인코더의 80%는 이해한 것이다. Position Encoding이나 Position-wise Feedfoward net은 encoder, decoder 모두에서 사용되는 기법이니 곧 설명할 예정이다.
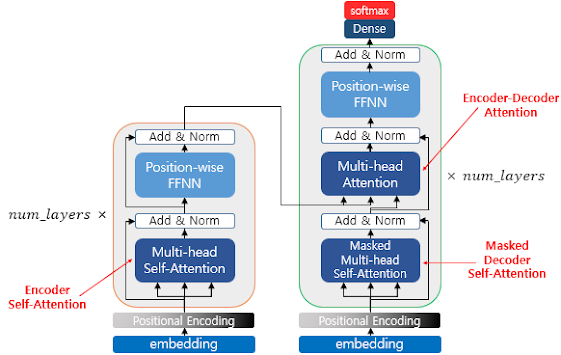
다시 한번 전체 모습을 살펴보면 Transformer는 3개의 attention을 가지고 있다.
layer normalization역시 CNN 포스트의Layer normalization과 동일한 개념이기 때문에 자세한 설명은 생략하도록 한다.
9. Positional Encoding
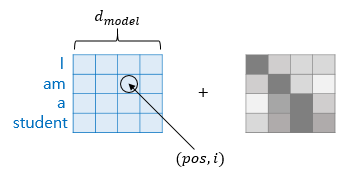
앞의 과정을 상기해보면, Transformer 모델은 input sequence의 단어를 마치 python의 dictionary형태로 저장해놓고 self attention을 수행하는 것을 알 수 있다. 그런데 여기서 문제점은 각 단어의 벡터가 key로 등록은 되는데 몇 번째 단어인지는 알 수가 없다. 예를 들어 위 그림에서 'am'을 key값으로 찾을 순 있지만 2번째 있는 단어라는 것은 알 수가 없는 것이다.
그래서 Transformation model에서는 Positional Encoding 값을 embedding(vectorized word)에 더해줌으로써 위치 정보를 만들어 준다. 이 과정을 시각화 하면 아래와 같다.
위 그림을 보면 오른쪽에 있는 단어일 수록 positional encoding 값도 오른쪽이 큰 것을 알 수 있다. 어떻게 해야 이런 값을 만들 수 있을까?
위 식은 단어위 위치 pos와 각 단어의 벡터의 index i가 주어졌을 때 Positional Encoding(PE)값을 구하는 방법이다. 식으로는 이해가 어려우니 예제를 한번 살펴보자.
위 예제는 각 단어를 4차원으로 embedding 한 것을 가정한 것이다. (논문에는 128차원으로 embedding 했다.) 그리고 각 단어 vector의 i번째 차원값은 sin과 cos의 변환하면서 계산되고, 계산 결과 위 그림처럼 출력된다. 이게 어떤 의미를 가질까? PE의 단순한 예를 하나 더 살펴보자.
만약 우리가 10진수를 2진수로 표현한다고 가정해 보자. 2진수의 자릿수를 10개 (=차원)으로 나타낸다고 하면 위 그림과 같이 변환할 수 있다.
i=1의 값은 1, 0, 1, 0 순으로 빠르게 변하고, i=2의 값은 1, 1, 0, 0, 1, 1 과 같이 조금 늦게, i=3인 값은 1, 1, 1, 1, 0, , ... 더 늦게 변화하는 것을 확인할 수 있다.
즉, word를 이런 방식으로 표현하면 만약 같은 단어가 2번 나왔더라도 어디쯤 위치한 word인지 알 수가 있다.
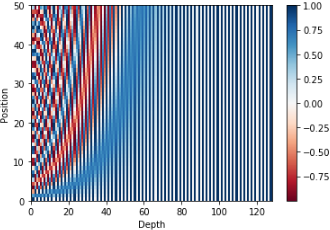
위 그림은 126차원으로 embedding된 50개의 단어을 Positional Encoding 시킨 결과이다.
우리는 각 단어의 PE된 vector가 어떤 값을 갖는지는 알 필요가 없다. 하지만 컴퓨터에게는 이 vector로 하여금 각 단어의 위치정보를 알 수 있게 해준다. (이 위치정보를 알게 해주는것이 핵심!!)
지금까지 각 구성요소에 대해서 각각 살펴봤는데 이제 전체그림으로 조립해보자.
vectorized 된 단어들이parameter를 가진 embedding으로 입력된다.
embedding된 단어가위치 정보를 담을 수 있도록 Positional Encoding된다.
각 단어의 vector가Self-Attention + FFNN되는데, 일종의"입력된 문장을 이해하는 과정"으로 볼 수 있다. 그리고 인코더는 num_layers만큼 쌓을 수 있다. ※ CNN으로 치면 Conv, Pooling을 반복하는 과정이다.
Encoder에서 출력된 Context vector를 통해 Decoder에서 단어를 예측하는데, 이 때는 Self-Attention이 아니라Encoder-Decoder Attention을 수행한다.
그리고Decoder에서 예측된 단어들은 매번 Self-Attention을 통해, 일종의"예측된 문장을 이해하는 과정"을 반복한다.
딥러닝에서 어떤 모델을 사용하든 모델을 분석하는 과정을 train code를 사용하거나 test code를 사용하는 와중에 값을 확인할 때, 일부 vison 모델에서는 결과값을 opencv로 확인하고 싶을 때의 과정을 정리했다.
여기서 사용한 모델은 Yolact모델이다. (Yolact 모델 정리는 추후 backbone정리가 마무리가 되면 진행할 예정.. fpn과정의 연산이 모듈형태로 foward연산이 자동으로 실행돼서 연산과정을 확인할 수 없어서 시간이 조금 걸릴것으로 예상됨)
여기서는 mask가 씌워지는 결과는 각각 확인하고 싶었다.
뭔가 마스크라는 변수에 15개(object)의 텐서가 들어가 있다 현재 이 연산은 Tensor형태로 gpu에서 연산중이니 opencv에서 확인하기 위해서는 변환하는 과정이 있어야 한다. gpu -> cpu(메모리에 값을 복사) -> byte() float형태의 값을 integer값으로 변환해줘야 opencv에서 사용가능 -> numpy (tensor값을 numpy로 변환해야 opencv에서 확인가능)
# 실제 코드
(masks[0]* 255).byte().cpu().numpy()
cv2.imshow("test1",(masks[0]* 255).byte().cpu().numpy())
cv2.waitKey(0)
변환결과
변과결과 확인
마스킹 형태가 잘 나온걸 확인할 수 있다.
p.s train이나 test중간의 값을 확인하기 하다가 보면 tensor값의 경우 torch.Size([4, 3, 32, 32]) 이런식으로 channel값이 바뀌어 있는 경우가 있는데 이 경우에는 opencv 형식으로 변환해줘야 한다.
# torch.Size([4, 3, 32, 32]) 일 때 train_t = np.transpose(train, (0, 2, 3, 1)) train_t.shape
포인터 소개 (Introduction to pointer) 변수는 값을 보유하고 있는 메모리 조각의 이름이라는 것을 배웠다. 프로그램이 변수를 인스턴스화 할때 사용 가능한 메모리 주소가 변수에 자동으로 할당되고, 변수에 할당된 값은 이 메모리 주소에 저장된다.
int x;
CPU가 위 문장을 실행하면 RAM의 메모리 조각이 따로 설정된다. 예를 들어 변수 x에 메모리 위치 140이 할당되었다고 가정해보자. 프로그램에서 변수 x를 표현식 또는 명령문으로 접근할 때마다 값을 얻으려면 메모리 위치 140을 찾아야 한다. 변수의 좋은 점은 우리가 어떤 특정한 메모리 주소가 할당되는지 걱정할 필요가 없다는 것이다. 지정된 식별자로 변수를 참조하면 컴파일러에서 이 이름을 할당된 메모리 주소로 변환한다. 하지만 이 접근법에는 몇 가지 제한 사항이 있으며, 이에 대해서는 앞으로 배울 내용에서 살펴보겠다.
주소 연산자 (&) (The address-of operator (&))
주소 연산자&를 사용하면 변수에 할당된 메모리 주소를 확인할 수 있다.
#include <iostream>
int main()
{
int x = 5;
std::cout << x << '\n'; // print the value of variable x
std::cout << &x << '\n'; // print the memory address of variable x
return 0;
}
// prints:
// 5
// 0027FEA0
역참조 연산자 (*) (The dereference operator (*))
변수의 주소를 얻는 것 자체로는 그다지 유용하지 않다.
역참조 연산자(*)를 사용하면 특정 주소에서 값에 접근할 수 있다.
#include <iostream>
int main()
{
int x = 5;
std::cout << x << '\n'; // print the value of variable x
std::cout << &x << '\n'; // print the memory address of variable x
std::cout << *&x << '\n'; /// print the value at the memory address of variable x
return 0;
}
// prints:
// 5
// 0027FEA0
// 5
포인터 (Pointer)
주소 연산자(&)와 역참조 연산자(*)와 함께 이제 포인터에 관해 이야기할 수 있다.
포인터는 어떠한 값을 저장하는 게 아닌 메모리 주소를 저장하는 변수다.
포인터(pointer)는 C++ 언어에서 가장 혼란스러운 부분 중 하나로 여겨지지만, 알고 보면 놀랍게도 간단한다.
간단하게 포인터에 대해서도 알아 보았으니 밑으로는 함수형과 구조체에서 간단하게 포인터를 사용하는 예제를 알아보자.
#include <iostream>
#include <cstddef>
void doSomething(double *ptr) // 메모리의 값이 복사됨
{
std::cout << "address of pointer varaibable in doSomething()" << &ptr << std::endl;
if (ptr != nullptr) {
// do something useful
std::cout << *ptr << std::endl;
}
else {
// do nothing with ptr
std::cout << "NULL ptr, do nothing" << std::endl;
}
}
int main()
{
double *ptr{ nullptr }; // modern c++ memoery1
doSomething(ptr);
doSomething(nullptr);
double d = 123.4;
doSomething(&d);
ptr = &d;
doSomething(ptr);
std::nullptr_t nptr;
// null pointer만 넣을 수 있음 혹시나 null pointer만 받아야하는 경우 사용하게 될 것 같음
std::cout << "address of pointer varaibable in main()" << &ptr << std::endl;
// 현재 여기서 사용하는 메모리 주소와 위의 주석처리 되어 있는 memory1의 메모리주소와 다름
// 복사되어서 사용하기 때문에 값은 같으나 엄연히 메모리 주소가 다르다.
return 0;
}