유튜브의 10분 딥러닝을 참고하여 정리하였습니다.
1. Attention Mechanism


인공신경망에서 Attention이라고 하는것은 어떤 특정한 신경망을 뜻하는것이 아니라 인간의 시각적 집중(Visual Attention) 현상을 구현하기위한 신경망적 기법을 말합니다.
Attention이 딥러닝 모델 혹은 layer가 아닌 기법인 이유
위의 그림과 같이 구현되어 있다고 가정한다면, 사람이 주목하는 부분에 대해서 고화질을 유지하고 그 이외의 영역에 대해서는 저화질을 유지하게 됩니다. 이 말을 다시 정리하자면, 우리의 초점이 맞는 곳 즉, 우리가 보고자 하는 영역에 대해서는 높은 집중도를 보여서 고화질을 유지하게되고 보지 않는것에 관해서는 낮은 저화질로 낮은 집중도를 유지하게 됩니다. 이러한 현상을 인공신경망에서도 구현을 해보고자 하는것이 Attention 기법이라고 할 수 있겠습니다.
2. 가중치와 어텐션의 공통점과 차이점
가중치도 결국 보고자하는 영역을 집중적으로 본다고 할 수 있는데 그럼 가중치를 학습하는것과 차이는 뭐야?
=> 가중치와 어텐션의 공통점과 차이점
가중치와 어텐션 모두 해당 값을 얼마나 가중시킬 것인가를 나타내는 역활을 하지만, 어텐션을 가중치와 달리 전체 또는 특정 영역의 입력값을 반영하여, 그 중에 어떤 부분에 집중해야 하는지를 나타내는 것을 목표로 한다. ( 어떻게 사용하냐에 따라서 선택적으로 사용할 수 있다는 부분이 다르다고 할 수 있겠다. )

좀 더 상세히 설명하자면 가중치의 경우 <Visual World> 의 이미지가 있다고 가정할 때 각 이미지의 모양, 형태에 집중하는것이 아닌 최종적으로 y와 얼마만큼 가까워지게 만들 수 있는지에 focus가 맞춰져 있다고 생각하시면 될 것 같습니다. 또 그 판단기준( y와 유사하게 만드는 값 )에 따라서 가중시킬것인지 축소시킬것인지가 결정됩니다. 하지만 어텐션의 경우 객체나 물체같은 경우를 인식해서 그 객체나 물체가 있는 특정영역만 집중을 하겠다라는게 어텐션의 컨셉이라고 생각하시면 됩니다.
3. 신경망 기계번역
Attention기법이 인공신경망에 어떻게 적용되는지 특정분야를 가지고 설명을 하도록 하겠습니다. 대표적인 분야로 자연어처리 분야를 예로 사용하겠습니다.

우리가 번역하고자하는 언어를 데이터로 사용해서 번역하고자 언어로 변역하는 시스템이 신경망 기계번역이라고 보시면 될 것 같습니다.
4. 기계번역에서의 어텐션 메커니즘

인코더-디코더 방식의 경우 인풋데이터를 특정 크기의 벡터 사이즈로 압축 후 디코더를 통해 원하는 출력값을 산출하게 된다. ( 특정 크기의 벡터 사이즈가 고정되는 이유는 특정 크기의 벡터 사이즈로 데이터를 압축해서 표현하기 위함. Encoder -Decoder에 관해서는 따로 자세히 설명할 예정 ) 여기서 고정된 크기의 벡터를 사용했을 때 보통 이 벡터의 사이즈가 사용된 데이터를 압축하는식으로 진행되기 때문에 데이터의 특징을 대표하는 feature이면서 동시에 데이터의 손실이 발생하게 된다. 이에 대해서 문제제기를 Neural Machine Translation By Jointly Learning To Align Translate논문에서 했으며, 이를 극복방안 중 하나로 Attention 기법을 제안하였다.
5. 기계번역에서의 어텐션 메커니즘 구조
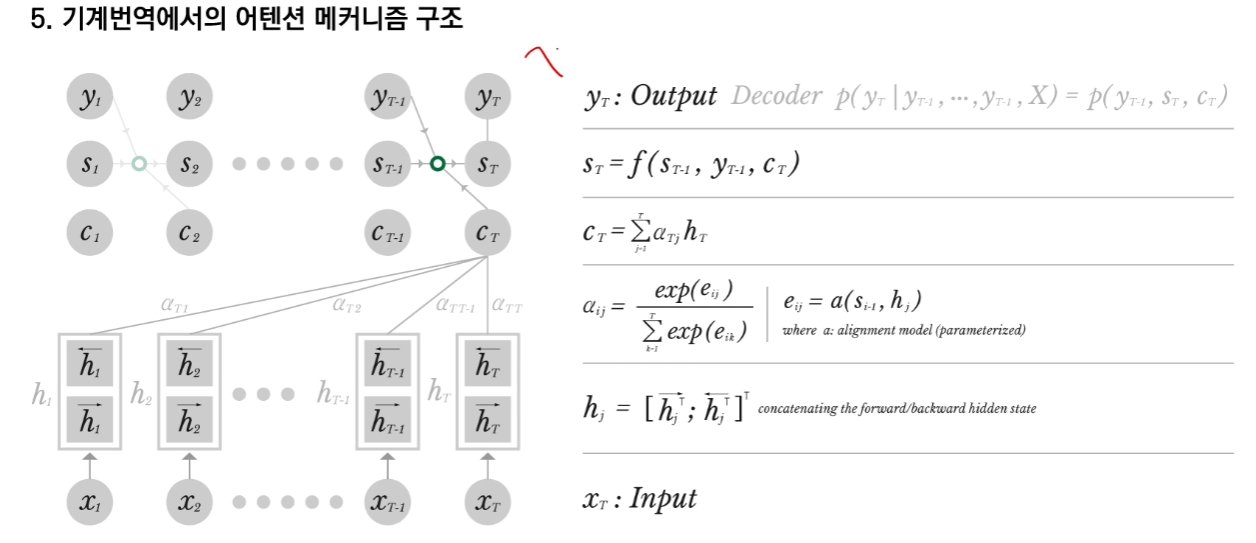
메커니즘 구조에 대해서 좀 더 자세히 설명하자면 X_1 ~ X_T 까지의 입력 데이터값이 주어지게 되면 RNN의 구조를 통해서 Hidden state 값을 뽑아내게 되는데, Hidden state 값의 경우 정방향 RNN에서 나온 Hidden state 값과 역방향 RNN에서 나온 Hidden state 값을 concatenate 이어붙여서 사용합니다.
위의 그림을 보시면 y의 경우에는 최종 출력물이고 s의 경우는 linear mapping을 한 상태 마지막으로 c의 경우 중간 값이라고 기억하시면 됩니다.
( 위의 구조 연산은 따로 좀 더 자세히 설명을 진행하도록 하겠습니다. Vision만하다보니 어텐션은 어렵네요...)
6. 어텐션 메커니즘의 의의
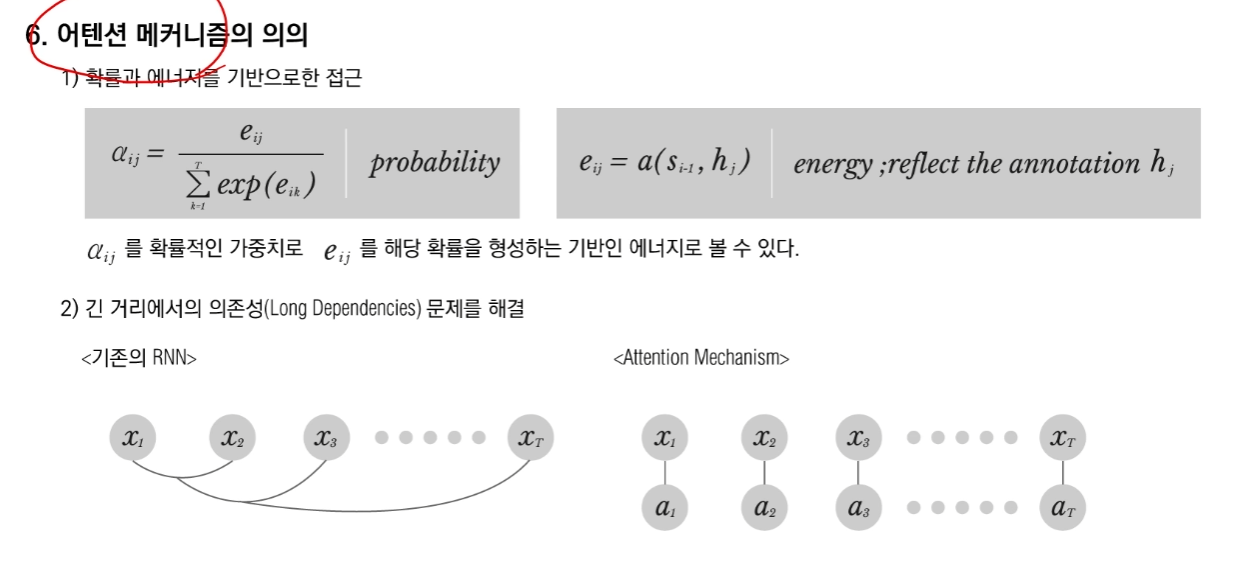
위의 수식을 보게 되면 어텐션을 사용하게 됐을 때, Softmax의 형태를 취하고 있음을 알 수 있습니다. 즉, 이말은 0~1사의 값을 가진다고 볼 수 있는데 이는 수학적으로 확률로 해석할 수 있음을 의미합니다.
기존의 RNN의 경우 연쇄적인 반영을 통해서 feedback시스템이 구성이 되기 때문에 길이가 길어질 경우 dependency가 생길 수 있지만 Attention의 경우 각각의 x에 따른 h를 뽑아내게 되고 각각의 a값에 따른 가중치들이 반영이 되기 때문에 기존의 RNN에 비해서 길어질 경우에 발생하는 부분을 조금 해소할 수 있을것 입니다.
참고 링크 : https://www.youtube.com/watch?v=6aouXD8WMVQ&ab_channel=10mindeeplearning
'nlp_study' 카테고리의 다른 글
| Transformer (0) | 2021.12.22 |
|---|