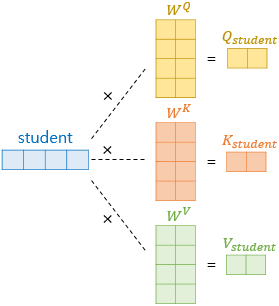
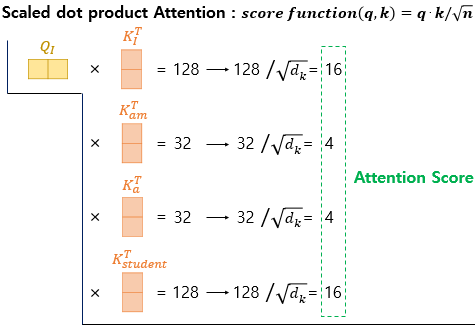
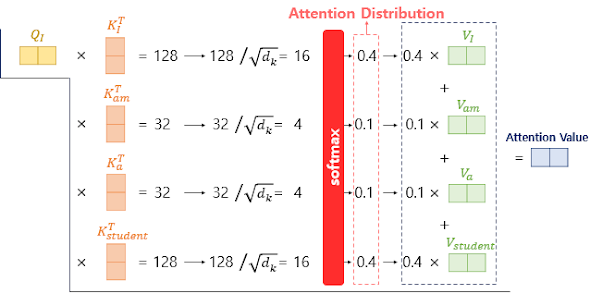
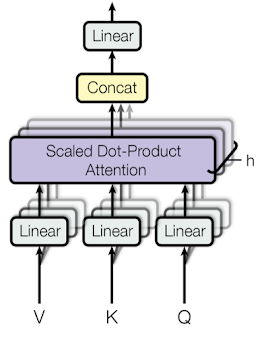
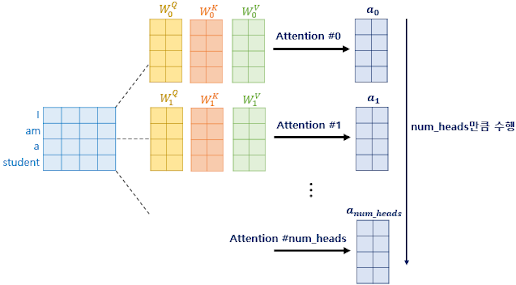
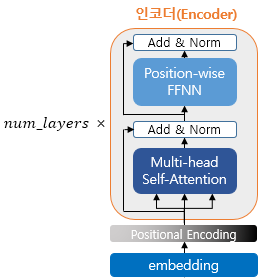
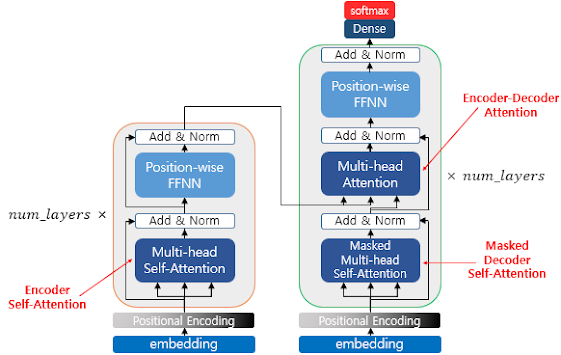
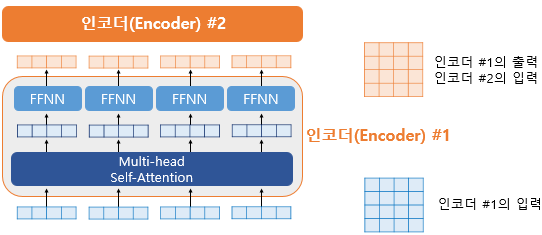
01) 토큰화(Tokenization)
Computer Vision과 달리 NLP에서 텍스트 자체를 바로 피처로 사용할 수는 없습니다. 사전에 텍스트 전처리 작업이 반드시 필요합니다. 텍스트 전처리를 위해서는 토큰화(tokenization) & 정제(cleaning) & 정규화(normalization)하는 일을 하게 됩니다. 이번에는 그중에서도 토큰화에 대해서 알아보도록 하겠습니다.
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 합니다. 그럼 먼저 말뭉치(Corpus, 코퍼스)의 뜻에 대해 먼저 알아보면
말뭉치 또는 코퍼스(영어: corpus, 복수형: corpora)는 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다. 컴퓨터의 발달로 말뭉치 분석이 용이해졌으며 분석의 정확성을 위해 해당 자연언어를 형태소 분석하는 경우가 많다. 확률/통계적 기법과 시계열적인 접근으로 전체를 파악한다. 언어의 빈도와 분포를 확인할 수 있는 자료이며, 현대 언어학 연구에 필수적인 자료이다. 인문학에 자연과학적 방법론이 가장 성공적으로 적용된 경우로 볼 수 있다.
형태 분석 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 형태 분석(形態分析)은 단어를 보고 형태소 단위로 분리해내는 과정을 말한다. 수작업으로 하기도 했으나 컴퓨터의 발달로 점차 자동화되어 정확도가 높아지
ko.wikipedia.org
어렵게 설명이 되어 있는데, 그냥 우리가 사용하는 텍스트 표본이라고 생각합시다.
토큰(Token)이란 문법적으로 더 이상 나눌 수 없는 언어 요소를 뜻합니다. 텍스트 토큰화(Text Tokenization)란 말뭉치로부터 토큰을 분리하는 작업을 뜻합니다.
예를 들어, 아이유의 노래 Love poem의 가사 중 "Here i am"이라는 말뭉치를 토큰화 한다고 가정하면 "Here", "i", "am" 이런 식으로 나뉘게 될 겁니다.(이상적인 경우)
텍스트 토큰화의 유형은 문장 토큰화와 단어 토큰화로 나눌 수 있습니다. 문장 토큰화는 텍스트에서 문장을 분리하는 작업을 뜻하고, 단어 토큰화는 문장에서 단어를 토큰으로 분리하는 작업을 뜻합니다.
문장 토큰화(Sentence Tokenization)
문장 토큰화는 문장의 마침표(.), 개행문자(\n), 느낌표(!), 물음표(?) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적입니다. 하지만 꼭 그렇지는 않습니다. 예를 들어, "Hello! I'm a Ph.D student."라는 텍스트를 문장 토큰화를 진행 할 경우 "Hello", "I'm a ph.D student"로 2개의 문장으로 분리를 해야 하는데, 마침표(.)를 기준으로 문장 토큰화를 하면 "Hello", "I'm a ph", "D student"로 3개의 문장으로 엉터리로 분리하게 됩니다. 따라서 100% 정확하게 문장을 분리하는 것은 쉬운 일이 아닙니다.
from nltk.tokenize import sent_tokenize
text = "His barber kept his word. But keeping such a huge secret to himself was driving him crazy. Finally, the barber went up a mountain and almost to the edge of a cliff. He dug a hole in the midst of some reeds. He looked about, to make sure no one was near."
print('문장 토큰화1 :',sent_tokenize(text))['His barber kept his word.', 'But keeping such a huge secret to himself was driving him crazy.', 'Finally, the barber went up a mountain and almost to the edge of a cliff.', 'He dug a hole in the midst of some reeds.', 'He looked about, to make sure no one was near.']3개의 문장이 잘 분류가 되고 있는 것을 확인할 수 있습니다. 위의 3 문장의 경우 단순히 마침표만으로 구분해도 구분할 수 있는 문장인데요. 중간에 마침표로 사용되지 않는 Ph.D가 포함된 문장도 토큰화를 진행해보도록 하겠습니다.
text_sample = 'I am actively looking for Ph.D. students. and you are a Ph.D student.'
tokenized_sentences = sent_tokenize(text_sample)
print('Ph.D.가 포함된 문장 토큰화 :',sent_tokenize(text_sample))Ph.D.가 포함된 문장 토큰화 : ['I am actively looking for Ph.D. students.', 'and you are a Ph.D student.']마침표(.)를 기준으로 분리하지 않았기 때문에 정확히 분리된 것을 볼 수 있습니다.
단어 토큰화 (Word Tokenization)
단어 토큰화는 기본적으로 띄어쓰기를 기준으로 합니다. 영어는 보통 띄어쓰기로 토큰이 구분되는 반면, 한국어는 띄어쓰기 만으로 토큰을 구분하기는 어렵습니다. 심지어 띄어쓰기가 잘못되어 있는 경우도 허다하고요. 우선은 영어를 기반으로 실습해보겠습니다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print('단어 토큰화1 :',word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))단어 토큰화1 : ['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']결과를 보시면 띄어쓰기를 기반으로 분리를 하되 콤마(,)와 마침표(.)는 별도의 토큰으로 구분했습니다. 어퍼스트로피(')가 있는 경우 Don't는 Do와 n't로 Jone's는 Jone'과 's로 구분했습니다.
마지막으로 nltk가 아닌 keras의 text_to_word_sequence로 실습해보겠습니다.
from keras.preprocessing.text import text_to_word_sequence
sentence = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."
words = text_to_word_sequence(sentence)
print("keras_text_to_word_sequence : ",words)keras_text_to_word_sequence : ["don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'mr', "jone's", 'orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']keras의 text_to_word_sequence는 모든 알파벳을 소문자로 바꾸고, 구두점(컴마, 마침표 등)을 없애고, 어퍼스트로피(')도 보존하여 토큰을 제대로 구분해준 것을 볼 수 있습니다.(성능이 괜찮네요)
문장 토큰화와 단어 토큰화 모두 정규 표현식을 활용하여 토큰화하는 작업도 가능합니다.(정규화를 쓸 경우에는 정교하게 진행해야 제공되는 api이상 혹은 비슷한 성능이 나올 겁니다.) 문장 토큰화는 문장 자체가 중요한 의미를 가질 경우 사용되며, 일반적으로는 단어 토큰화만 사용해도 충분합니다.
영어는 해봤으니 앞으로 사용할 한국어의 경우에는 박상길님이 개발한 KSS(Korean Sentence Splitter)를 '딥러닝을 이용한 자연어 처리 입문'에서 추천하고 있습니다. KSS를 설치합니다.
pip install kssKSS를 통해서 문장 토큰화를 진행해보겠습니다.
import kss
text = '아이유의 2022년도 콘서트 이름은 골든아워입니다. 저번주 주말에 갔는데 팬들에게 방석을 나눠주더라구요. 저는 연두색 방석을 받았습니다.'
print('한국어 문장 토큰화 :',kss.split_sentences(text))한국어 문장 토큰화 : ['아이유의 2022년도 콘서트 이름은 골든아워입니다.', '저번주 주말에 갔는데 팬들에게 방석을 나눠주더라구요.', '저는 연두색 방석을 받았습니다.']출력 결과는 정상적으로 모든 문장이 분리된 결과를 보여줍니다. (조금 애매한 문장을 잘 안나뉘는 케이스들도 있습니다. 참고하시기 바래요.)
한국어에서의 토큰화의 어려움
영어는 New York과 같은 합성어나 he's 와 같이 줄임말에 대한 예외처리만 한다면, 띄어쓰기(whitespace)를 기준으로 하는 띄어쓰기 토큰화를 수행해도 단어 토큰화가 잘 작동합니다. 거의 대부분의 경우에서 단어 단위로 띄어쓰기가 이루어지기 때문에 띄어쓰기 토큰화와 단어 토큰화가 거의 같기 때문입니다.
하지만 한국어는 영어와는 달리 띄어쓰기만으로는 토큰화를 하기에 부족합니다. 한국어의 경우에는 띄어쓰기 단위가 되는 단위를 '어절'이라고 하는데 어절 토큰화는 한국어 NLP에서 지양되고 있습니다. 어절 토큰화와 단어 토큰화는 같지 않기 때문입니다. 그 근본적인 이유는 한국어가 영어와는 다른 형태를 가지는 언어인 교착어라는 점에서 기인합니다. 교착어란 조사, 어미 등을 붙여서 말을 만드는 언어를 말합니다.
1) 교착어의 특성
예를 들어봅시다. 영어와는 달리 한국어에는 조사라는 것이 존재합니다. 예를 들어 한국어에 그(he/him)라는 주어나 목적어가 들어간 문장이 있다고 합시다. 이 경우, 그라는 단어 하나에도 '그가', '그에게', '그를', '그와', '그는'과 같이 다양한 조사가 '그'라는 글자 뒤에 띄어쓰기 없이 바로 붙게됩니다. 자연어 처리를 하다보면 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식이 되면 자연어 처리가 힘들고 번거로워지는 경우가 많습니다. 대부분의 한국어 NLP에서 조사는 분리해줄 필요가 있습니다.
띄어쓰기 단위가 영어처럼 독립적인 단어라면 띄어쓰기 단위로 토큰화를 하면 되겠지만 한국어는 어절이 독립적인 단어로 구성되는 것이 아니라 조사 등의 무언가가 붙어있는 경우가 많아서 이를 전부 분리해줘야 한다는 의미입니다.
한국어 토큰화에서는 형태소(morpheme) 란 개념을 반드시 이해해야 합니다. 형태소(morpheme)란 뜻을 가진 가장 작은 말의 단위를 말합니다. 이 형태소에는 두 가지 형태소가 있는데 자립 형태소와 의존 형태소입니다.
- 자립 형태소 : 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소. 그 자체로 단어가 된다. 체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사 등이 있다.
- 의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간를 말한다.
예를 들어 다음과 같은 문장이 있다고 합시다.
- 문장 : 에디가 책을 읽었다
이 문장을 띄어쓰기 단위 토큰화를 수행한다면 다음과 같은 결과를 얻습니다.
- ['에디가', '책을', '읽었다']
하지만 이를 형태소 단위로 분해하면 다음과 같습니다.
자립 형태소 : 에디, 책
의존 형태소 : -가, -을, 읽-, -었, -다
'에디'라는 사람 이름과 '책'이라는 명사를 얻어낼 수 있습니다. 이를 통해 유추할 수 있는 것은 한국어에서 영어에서의 단어 토큰화와 유사한 형태를 얻으려면 어절 토큰화가 아니라 형태소 토큰화를 수행해야한다는 겁니다.
2) 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
사용하는 한국어 코퍼스가 뉴스 기사와 같이 띄어쓰기를 철저하게 지키려고 노력하는 글이라면 좋겠지만, 많은 경우에 띄어쓰기가 틀렸거나 지켜지지 않는 코퍼스가 많습니다.
한국어는 영어권 언어와 비교하여 띄어쓰기가 어렵고 잘 지켜지지 않는 경향이 있습니다. 그 이유는 여러 견해가 있으나, 가장 기본적인 견해는 한국어의 경우 띄어쓰기가 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어라는 점입니다. 띄어쓰기가 없던 한국어에 띄어쓰기가 보편화된 것도 근대(1933년, 한글맞춤법통일안)의 일입니다. 띄어쓰기를 전혀 하지 않은 한국어와 영어 두 가지 경우를 봅시다.
EX1) 제가이렇게띄어쓰기를전혀하지않고글을썼다고하더라도글을이해할수있습니다.
EX2) Tobeornottobethatisthequestion
영어의 경우에는 띄어쓰기를 하지 않으면 손쉽게 알아보기 어려운 문장들이 생깁니다. 이는 한국어(모아쓰기 방식)와 영어(풀어쓰기 방식)라는 언어적 특성의 차이에 기인합니다. 이 책에서는 모아쓰기와 풀어쓰기에 대한 설명은 하지 않겠습니다. 다만, 결론적으로 한국어는 수많은 코퍼스에서 띄어쓰기가 무시되는 경우가 많아 자연어 처리가 어려워졌다는 것입니다.
품사 태깅(Part-of-speech tagging)
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기도 합니다. 예를 들어서 영어 단어 'fly'는 동사로는 '날다'라는 의미를 갖지만, 명사로는 '파리'라는 의미를 갖고있습니다. 한국어도 마찬가지입니다. '못'이라는 단어는 명사로서는 망치를 사용해서 목재 따위를 고정하는 물건을 의미합니다. 하지만 부사로서의 '못'은 '먹는다', '달린다'와 같은 동작 동사를 할 수 없다는 의미로 쓰입니다. 결국 단어의 의미를 제대로 파악하기 위해서는 해당 단어가 어떤 품사로 쓰였는지 보는 것이 주요 지표가 될 수도 있습니다. 그에 따라 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분해놓기도 하는데, 이 작업을 품사 태깅(part-of-speech tagging)이라고 합니다. NLTK와 KoNLPy를 통해 품사 태깅 실습을 진행합니다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
print('단어 토큰화 :',tokenized_sentence)
print('품사 태깅 :',pos_tag(tokenized_sentence))단어 토큰화 : ['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D.', 'student', '.']
품사 태깅 : [('I', 'PRP'), ('am', 'VBP'), ('actively', 'RB'), ('looking', 'VBG'), ('for', 'IN'), ('Ph.D.', 'NNP'), ('students', 'NNS'), ('.', '.'), ('and', 'CC'), ('you', 'PRP'), ('are', 'VBP'), ('a', 'DT'), ('Ph.D.', 'NNP'), ('student', 'NN'), ('.', '.')]한국어 자연어 처리를 위해서는 KoNLPy(코엔엘파이)라는 파이썬 패키지를 사용할 수 있습니다. 코엔엘파이를 통해서 사용할 수 있는 형태소 분석기로 Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)가 있습니다.
한국어 NLP에서 형태소 분석기를 사용하여 단어 토큰화. 더 정확히는 형태소 토큰화(morpheme tokenization)를 수행해보겠습니다. 여기서는 Okt와 꼬꼬마 두 개의 형태소 분석기를 사용하여 토큰화를 수행하겠습니다.
from konlpy.tag import Okt
from konlpy.tag import Kkma
okt = Okt()
kkma = Kkma()
print('OKT 형태소 분석 :',okt.morphs("아이유 콘서트는 최고입니다."))
print('OKT 품사 태깅 :',okt.pos("아이유 콘서트는 최고입니다."))
print('OKT 명사 추출 :',okt.nouns("아이유 콘서트는 최고입니다."))OKT 형태소 분석 : ['아이유', '콘서트', '는', '최고', '입니다', '.']
OKT 품사 태깅 : [('아이유', 'Noun'), ('콘서트', 'Noun'), ('는', 'Josa'), ('최고', 'Noun'), ('입니다', 'Adjective'), ('.', 'Punctuation')]
OKT 명사 추출 : ['아이유', '콘서트', '최고']'nlp_study > 입문(딥러닝을 이용한 자연어처리 입문)' 카테고리의 다른 글
| 01. 자연어 처리 입문 준비 (1) | 2022.09.26 |
|---|