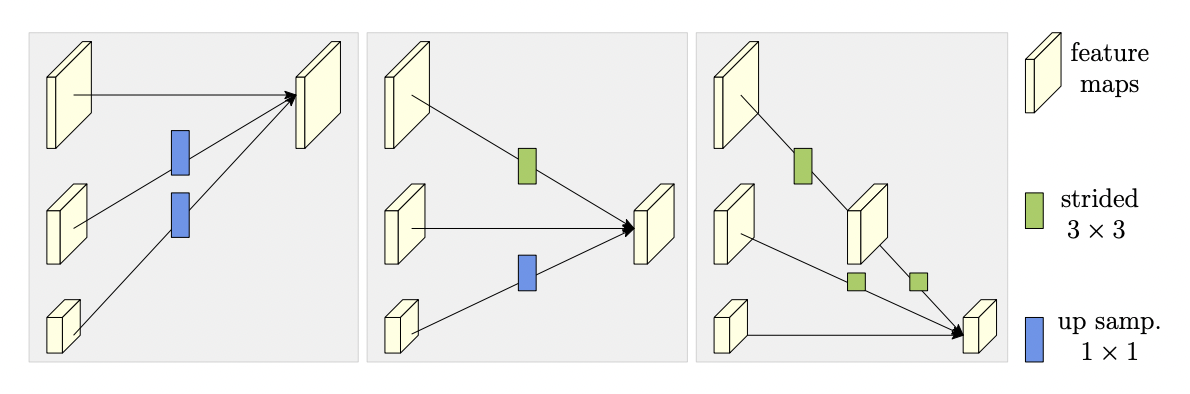
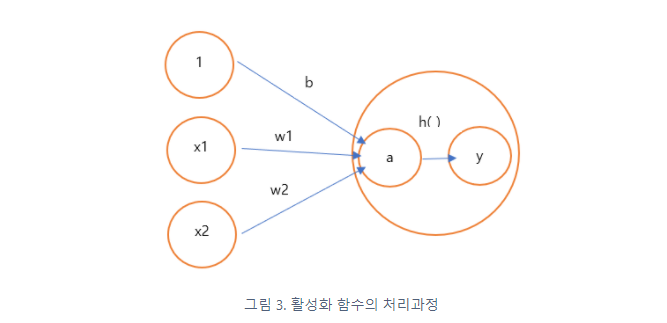
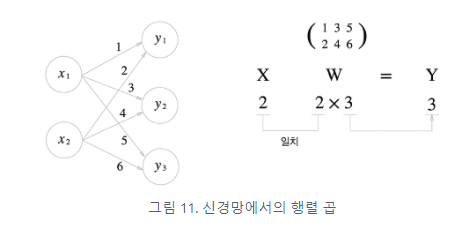
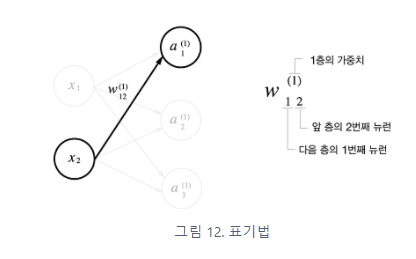
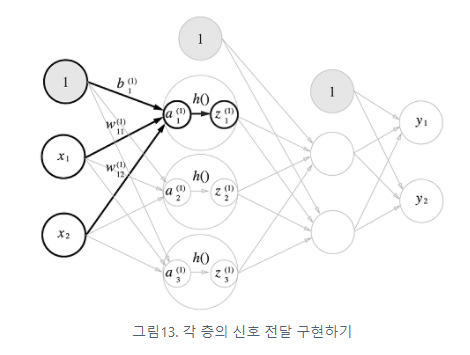
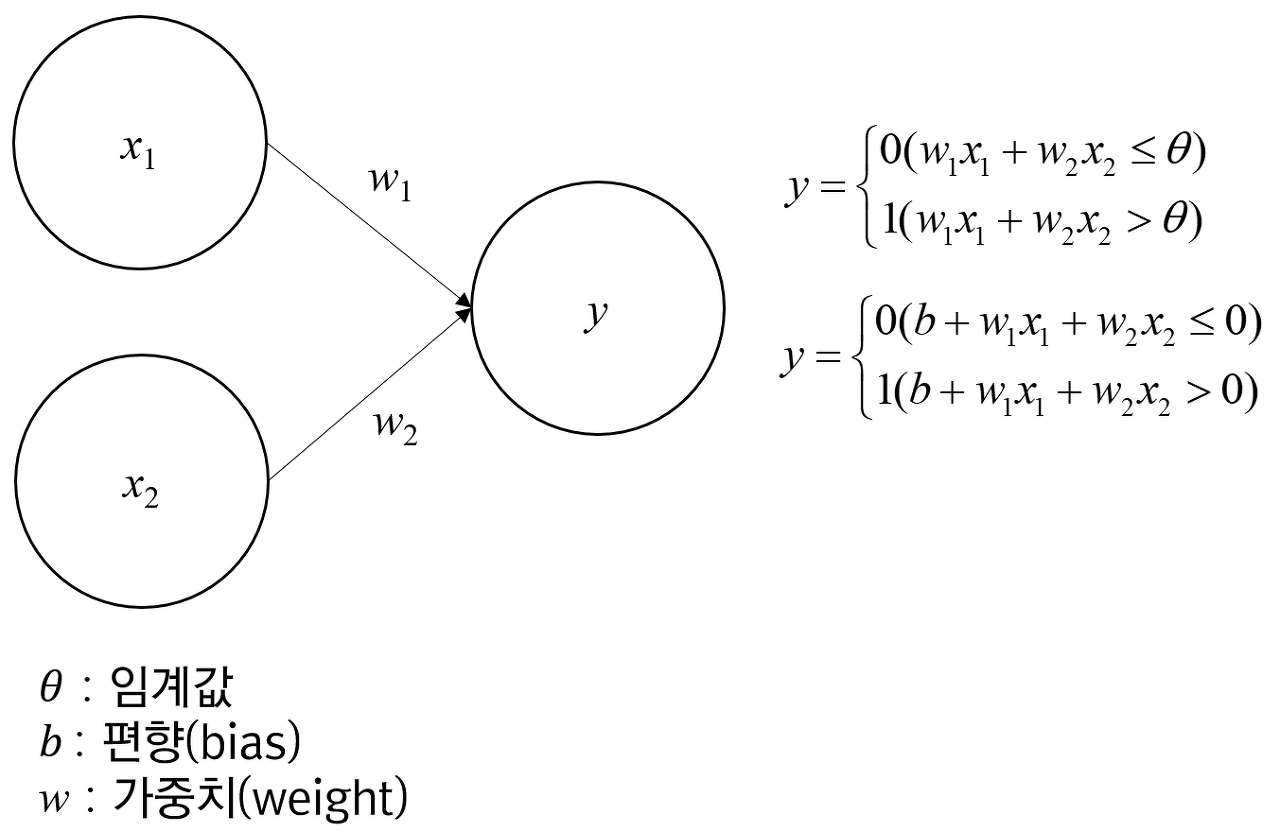
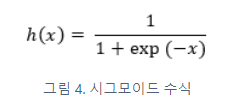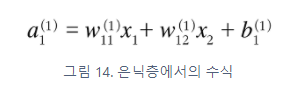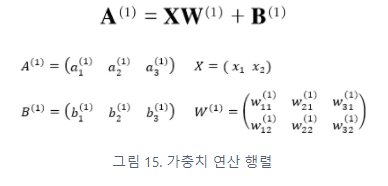anchor based 방식의 흐름

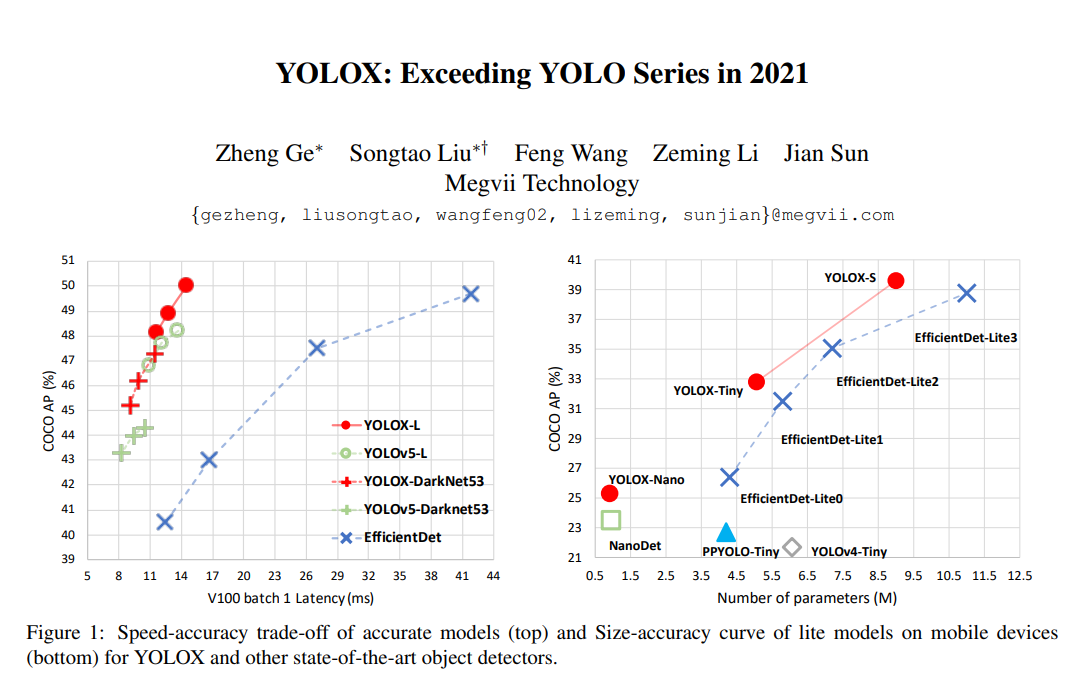
왼쪽 그래프의 성능을 보게 되면 SOTA 모델인 EfficientDet 모델보다 성능이 월등히 높게 나온것을 알 수 있습니다.
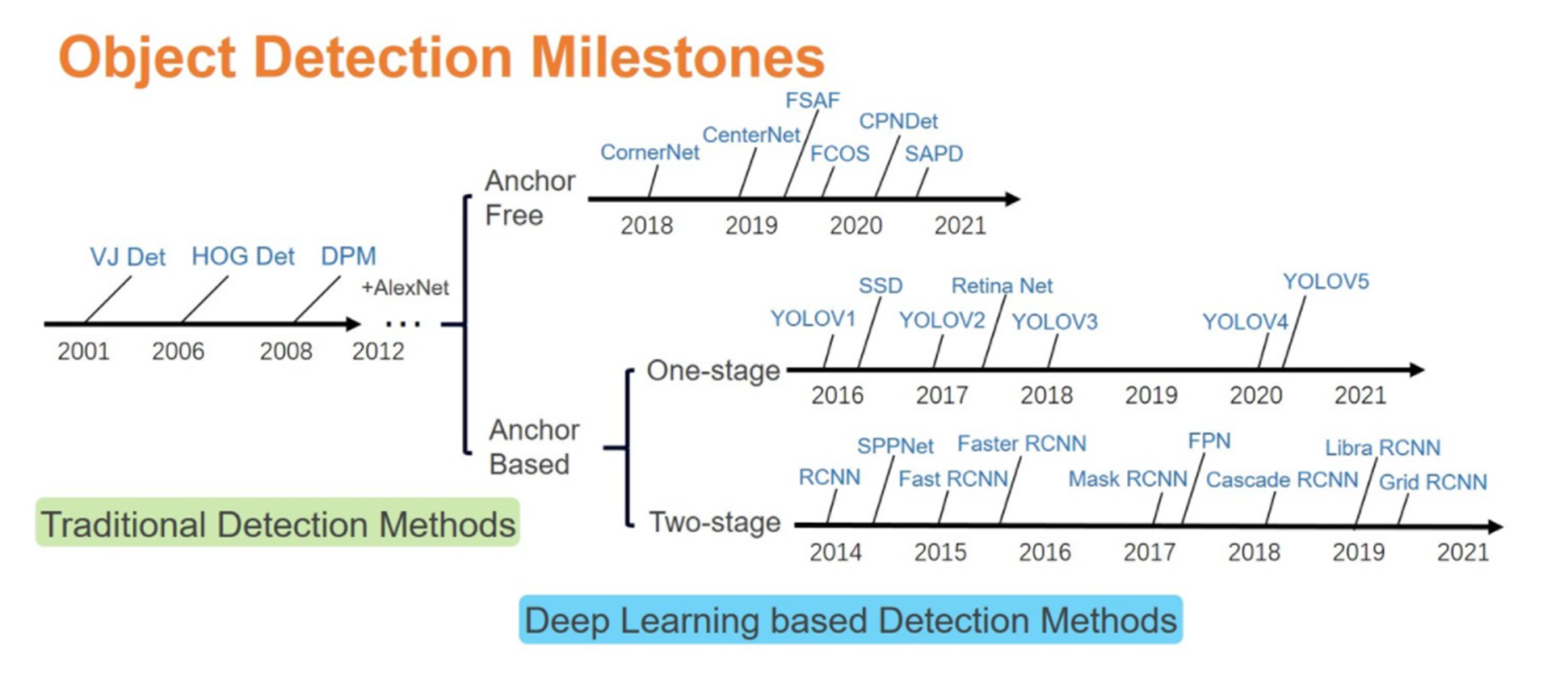
(먼저 간단하게 YOLO의 역사에 대해서 언급하고 시작하겠습니다.)
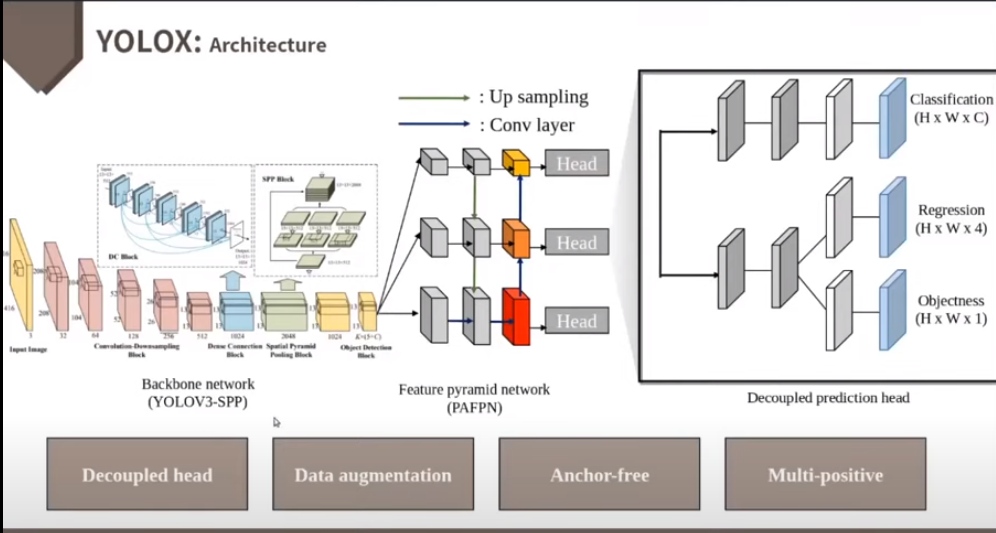
2개의 branch로 나눈 다음에
1. Introduction / brief history of YOLO
- YOLO(You Only Look Once)는 이미지 전체를 한번에 처리하는 Object Detection의 대표적인 1-Stage Approach
- Real-time Object Detection으로 큰 주목
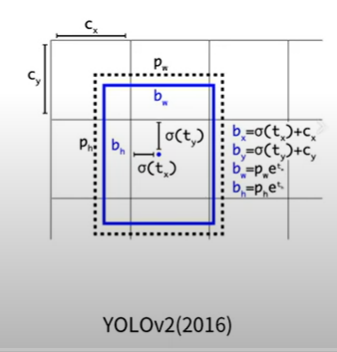
- 그 후 해를 거듭하며 발전 ( YOLOv1, v2, v3, v4, v5, PP-YOLO, ... )
- 최근에 트랜스포머 계열의 모델들이 Object Detection 태스크에 들어오기 전에는 대부분의 Object Detection 모델들은 CNN개반으로 수행했는데, 이번에 다루는 YOLO 역시 대표적인 CNN 기반의 네트워크

해당 모델이 어떻게 발전했는지를 간단하게만 소개해 드리자면,

1. Introduction / YOLOX Overview
- 최근 2년동안 연구자들은 Anchor-Free Detector, Advanced Label Assignment Strategy, End-to-end Detector의 연구에 주목하였지만 YOLO 시리즈에는 적용되지 않음
- 따라서 본 논문에서는 그러한 좋은 기법들을 적용하여 성능 개선에 목적을 두었다.
- Key concepts
- Anchor-free 방식의 Yolo구조
- Object Detection을 위한 발전 기술 적용 :
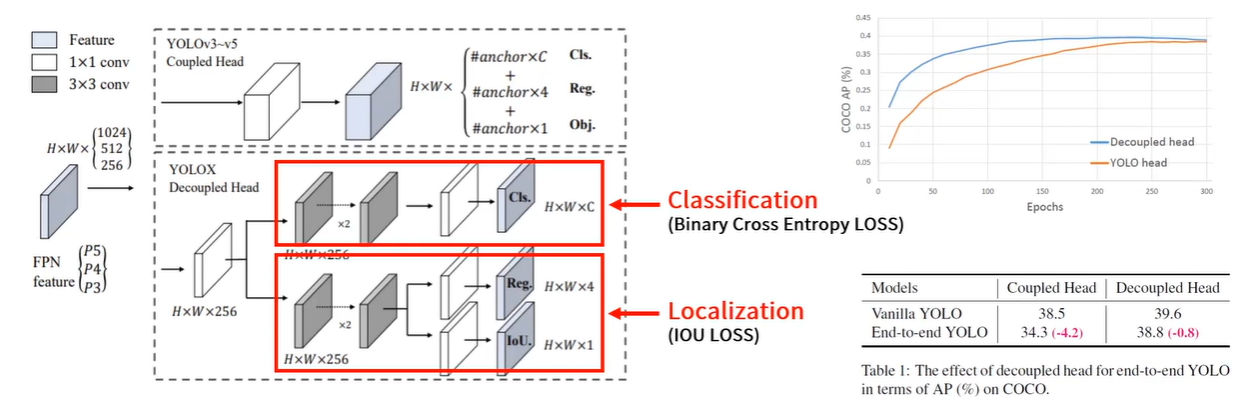
- Decoupled head ( head를 분리 )
- 발전된 Label assignment 기법 적용 : SimOTA
- 강력한 data augmentation : Mosaic, Mixup
- YOLOv3 baseline
- YOLOv4, v5가 anchor-based 파이프라인에 과도하게 최적화 될 수 있음을 고려하여 YOLOv3-SPP를 base architecture로 선정
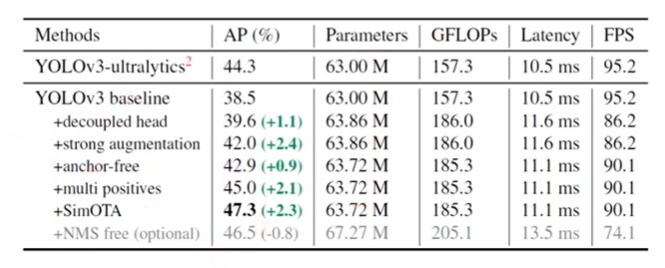
2. Network Design / Architecture
- Architecture
- Backbone : Darknet53
- Neck :SPP(Spatial Pyramid Pooling) + FPN(Feature Puramid Network)
- Head : YOLOv3 + Decoupled head
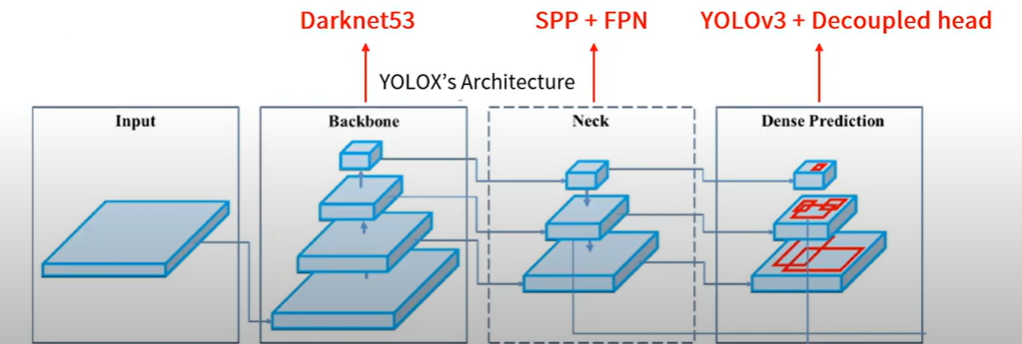
해당 관련 논문 : https://arxiv.org/abs/1903.08589 참고 바랍니다.
- 먼저 Backbone인 DarkNet에서 feature map을 추출합니다.
- Neck에서는 위에 그림과 같이 공간구조의 정보를 유지는 SPP Layer를 사용합니다. ( 이와 관련된 내용은 추후 추가적으로 다룰 예정)
- 그리고 FPN을 통해 멀티 스케일 Feature map을 얻을 수 있습니다.
- Feature에 대한 성숙도가 낮은 아래의 Feature map의 문제를 개선할 수 있는데요. high level의 extraction 정보를 더함으로써 아래의 Feature map이 지니고 있는 위치정보를 같이 활용할 수 있습니다.
- Dense Prediction을 보게 되면 위에서부터 큰 물체, 중간 물체, 작은 물체 순으로 detection하는 feature map
2. Network Design / Anchor-free
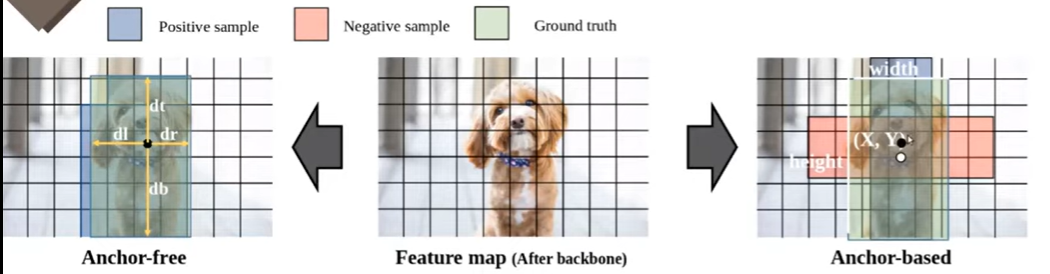
가운데 그림이 Backbon network를 거친 최종 피쳐맵을 의미합니다,
좌측의 경우 Anchor-free 우측의 경우가 Anchor-based 방법을 나타내고 있습니다.

Anchor-based
위의 그림을 보게 되시면 검은 점에서 prediction을 진행한다고 가정을 했을 때, 해당 Cell에서 Regression을 진행 후 나온 output값을 바탕으로 Anchor의 중심점과 가로와 세로의 길이를 결과적으로 bounding box의 가로 세로 길이와 중심점을 학습한다고 보시면 됩니다. ( 이는 네트워크마다 조금씩 다를 순 있습니다.) 여기서 예시를 보게 되면 하나의 Anchor box가 빨간색 박스와 파란색 박스를 만들었다는 걸 의미합니다. 여기서는 초로색 GT box와 초록색 box의 iou값이 높기 때문에 파란색 bounding box가 Positive 샘플로 분류가 됩니다. 빨간색 box는 학습에 참여하지 않음
Anchor-free
위와는 조금 다르게 Anchor-free에서는 GT box안에 있는 Cell들이 전부 Positive 샘플이 됩니다. 예를 들어 위에 그림과 같이 검은 점에서 prediction을 진행 한다고 했을 때, 해당 Cell에서부터 Ground Truth의 각 모서리까지의 길이를 학습하게 됩니다. 이를 바탕으로 Detectiion Task를 수행하게 됩니다.

- Anchor-based design의 단점
- 도메인에 specific해서 다른 데이터에 generalization 어려움 ( 최적의 anchor box 배치가 그 도매인에 specific하게 만듬 ) - ex) 데이터 셋에 따라서 aspect ratio 비율이 달라질 수 있음
- head의 복잡성과 예측의 수를 증가
- FCOS 방식의 Anchor-free design 적용
- FCOS[1]는 anchor-based detector의 단점을 개선한 anchor-free detector
- Bounding box regression의 범위를 feature level에 따라 pre-define
- 같은 위치에서 여러 개의 bounding box detect 가능

위의 그림을 추가적으로 설명하자면 YOLOX에서는 같은 포인트에서 두개의 Bounding box를 예측할 수 있는데, 그 이유는 낮은 feature level에서 하나만 예측하도록 ranage를 제한. 즉, feature level에 따라 range가 pre-define
2. Network Design / Architecture
- Object detection에서 Classification과 Regression이 서로 상충하는 문제가 존재함[1](아래 논문 참고)
Rethinking Classification and Localization for Object Detection
Two head structures (i.e. fully connected head and convolution head) have been widely used in R-CNN based detectors for classification and localization tasks. However, there is a lack of understanding of how does these two head structures work for these tw
arxiv.org
- Head를 Classification과 Regression으로 분리하고 IoU를 추가
- feature map의 결과를 256 Channel로 줄이고 3x3 Conv를 지나는 2개의 branch를 추가
- Classification에는 Binary Cross Entropy Loss를 사용해서 각각의 clss에 대한 확률이 나옴
- Localization에서는 IOU Loss를 사용하여 Bounding Box에 대한 종횡거리가 나오게 됨
- Loclization의 경우 Regression과 Objectness를 포함
- Regression Bounding Box에 대한 종횡거리
- Objectness의 경우 해당 cell이 백그라운드를 나타내는지 아니면 어떠한 오브젝트라도 포함하는지를 0~1사의 value로 표현
- Loclization의 경우 Regression과 Objectness를 포함
- YOLOv3~v5에서 1개였던 기존 head를 분리하면서 수렴 속도와 end-to-end의 AP를 항샹시킴
3. Training Strategies / Strong data augmentation


저자는 여기서 총 4가지의 Data augmentation의 방법을 적용하였습니다.
1. Random horizon flip
2. Color jitter ( 원본 영상의 hsl을 변경하여 증강시키는 클러스터라는 방법 )
3. Mosaic ( 원본 이미지외에 3개의 추가적인 사진을 섞는 방법 )
4. Mixup ( 이미지랑 레이블에 다른 거를 조금씩 섞는 방법 )
( 강력한 Data aumentation을 사용해서 그런지 몰라도 pre-trained weight를 사용해도 성능향상이 별로 일어나지 않아서 scratch 학습을 진행했다고 하는데 일반적인 데이터 셋인 코코 데이터 셋에서 이러한 현상이 발견된 점은 신기합니다. )
3. Training Strategies / Multi-positive
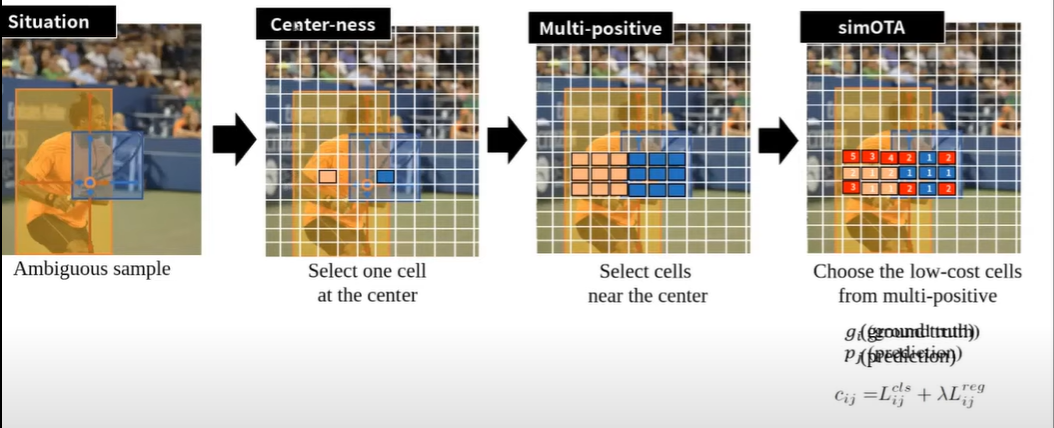
기본적인 Ancor free 방법만으로는 Anchor-based의 정확성을 따라잡기 힘듬에 따라 여러 방법들을 적용하게 됨
1. Center-ness ( FCOS 논문에서 처음 제안)
- 위의 사진과 같이 동그라미 점의 cell이 prediction하고자 하는 cell이라면 오브젝트 레이블이 좀 불분명한 점이 있습니다. 이러한 문제 때문에 detection ratio가 떨어진다고 생각해서 FCOS 저자는 positive한 셀들중에서 오브젝트의 중심에 해당하는 셀들만 positive로 할당하는 Center-ness 방법을 사용해서 정확도를 좀 더 항샹 시킴
2. Multi-positive
- 중앙에 있는 셀 말고도 그 주위에서도 좋은 prediction을 할 수 있는 셀들을 사용하는 방법. 센터 말고 주위의 셀들도 prediction하는 방법
3. simOTA
- 각 cell의 loss를 구해서, 각 Cell에서 Loss가 조금 낮은 애들만 top k를 뽑아서 학습시키는 방법. 예를 들어 그림에서처럼 사람 cell에 해당하는 9개의 sample중에서 5개는 loss가 낮은데 이 낮은 친구들을 positive sample로 사용하자는 의미. 라켓에 해당하는 cell의 경우도 파란색으로 5개가 loss가 낮음 이 친구들을 positive sample로 사용하자!!
4. Experimental results
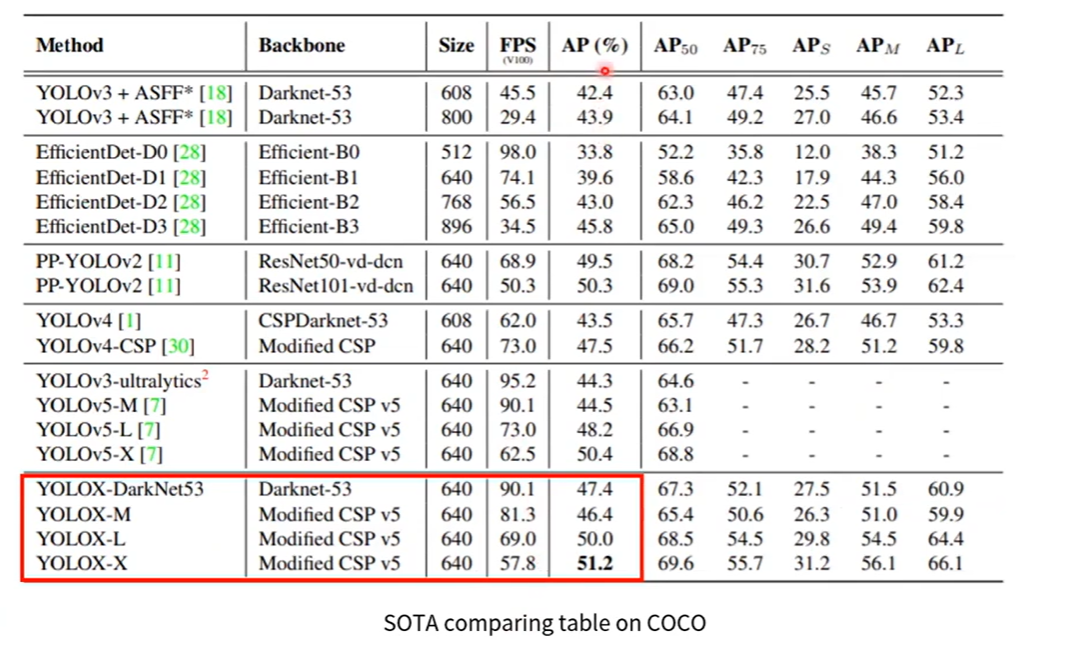
5. Conclusion
- 이 논문에서 anchor-free detector를 사용하여 YOLO 시리즈의 업데이트 버전을 제안
- 최근 고도화된 detection 기술인 decoupled head, advanced label assigning strategy등을 사용해 속도와 정확성이 전반적으로 훌륭한 성능을 보임
- 전반적으로 널리 쓰이는 YOLOv3의 아키텍쳐를 사용해서 AP(COCO)를 SOTA 최고로 개선시킴
'논문' 카테고리의 다른 글
| Pose Estimation - HRNet 논문리뷰 (0) | 2022.05.02 |
|---|---|
| ResNet - 논문리뷰 (0) | 2021.12.23 |