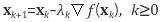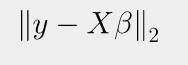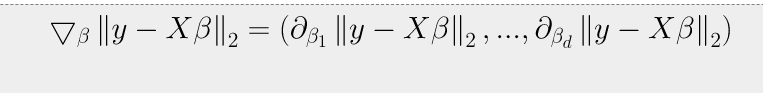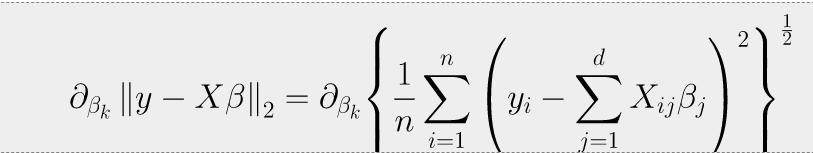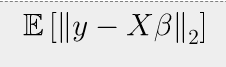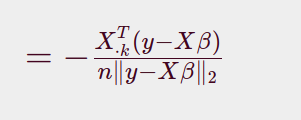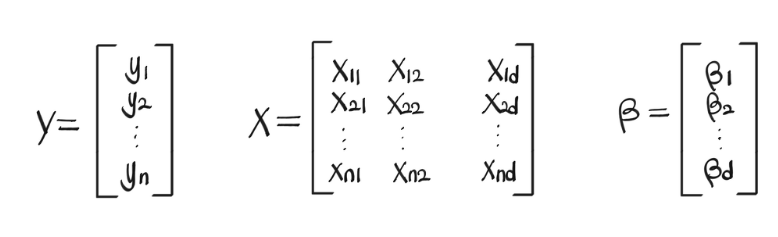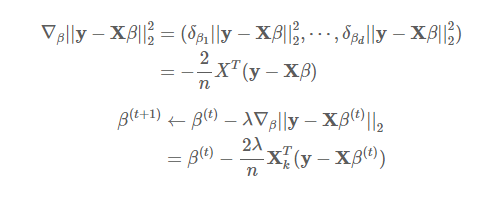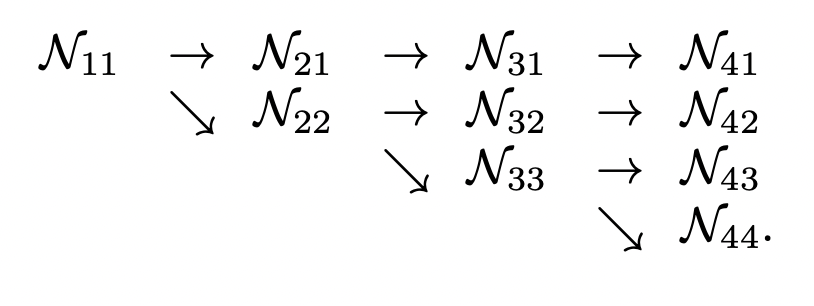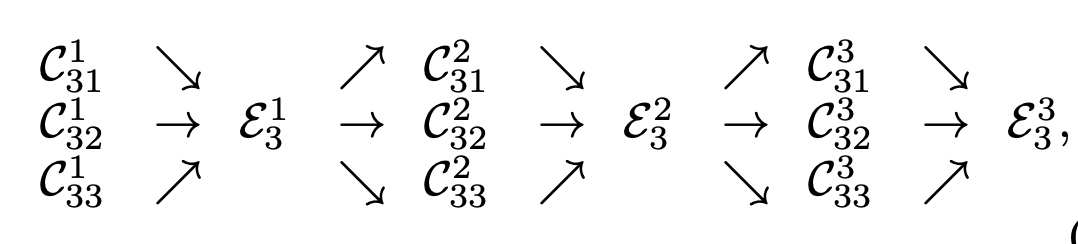신경망의 훈련은 신경망의 구조, 최적화 방법, 그리고, 가중치 초기화 등 다양한 변수의 영향을 받습니다. 즉, 네트워크를 어떻게 설정하느냐에 따라 신경망의 훈련은쉬울수도, 어려울 수도있습니다. ( 또한, 해당 모델에서 학습하고자 하는 목표에 대한 정의 및 어떤 loss fuction을 사용할지, 그리고 어떻게 사용할지도 고민을 같이 진행해야 합니다.)
배경 지식
Loss Surface를 알기 위해서 공부해야 되는 개념은 Loss function이다. (Cost function이라고도 일컫어진다.)
Loss function은 모델이 내놓은 예측값과 실제 정답이 얼마나 다른지를 나타내는 지표로서 정의된다. (모델 학습의 목표는 loss값을 최소화하는 W,B를 찾는 것이다)
Loss function은 대표적으로 MSE(Mean Squared Error)와 CEE(Cross Entropy Error)가 자주 사용되며, 그 외 다양한 loss function이 존재한다.
Loss Surface란
딥러닝에서 모델은 Loss function의 내놓은 값(Loss)을 줄이는 방향으로 학습이 진행된다.
이 과정에서 parameter가 변함에 따라서 loss값이 변하게 되는데, parameter 개수가 2개이하가 아닌이상 사람이 알아볼 수 있는 형태로 loss 그래프를 그리기가 어렵다.
아래 예시는 parameter가 2개일때 loss값(z축)이 어떻게 변하는지를 나타낸 그림이고 loss값들로 이루어진 surface를 loss surface라고 한다.
Loss Surface 만드는 법
Loss Surface를 시각화하는 방법은두개의 가우시안 분포를 따르는 랜덤 방향 벡터를 만드는 것입니다. (0,0) 의 중앙 지점은 이미 훈련된 파라미터에서의 Loss 값으로 최저점을 의미한다고 볼 수 있습니다. 두개의 방향 벡터를 만든 뒤, 각 방향벡터에 -1 부터 1까지의 상수를 곱하고, 기존 네트워크의 학습된 파라미터와 더하여 Loss Surface 를 시각화 합니다.
기본적인 함수 최적화(optimization) 방법 중 하나인 gradient descent 방법에 관한 글입니다.
Gradient descent 방법은 미분의 개념을 최적화 문제에 적용한 대표적 방법 중 하나로서 함수의 local minimum을 찾는 방법 중 하나입니다. Gradient descent 방법을 다른 말로 steepest descent 방법이라고도 부릅니다.
기본개념은 함수의 기울기(경사)를 구하고 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것입니다.
딥러닝 머신러닝 Task에서 Gradient Descent 종류 이런 것 보다 먼저, 일반적인 설명 수학적인 부분을 고려해가면서 공부 겸 설명을 이어가도록 하겠습니다. ( 제가 여러 책 및 블로그 등을 정리하면서 작성한 글입니다. 맨 마지막에 출처를 기재할 테니 참고하시기 바랍니다.)
0.gradient descent의 목적과 사용 이유
gradient descent는 함수의 최소값을 찾는 문제에서 활용된다.
함수의 최소, 최댓값을 찾으려면 “미분계수가 0인 지점을 찾으면 되지 않느냐?”라고 생각할 수 있습니다. 하지만 미분계수가 0인 지점을 찾는 방식이 아닌 gradient descent를 이용해 함수의 최솟값을 찾는 주된 이유는
우리가 주로 실제 분석에서 맞딱드리게 되는 함수들은 닫힌 형태(closed form)가 아니거나 함수의 형태가 복잡해 (가령, 비선형함수) 미분계수와 그 근을 계산하기 어려운 경우가 많고,
실제 미분계수를 계산하는 과정을 컴퓨터로 구현하는 것에 비해 gradient descent는 컴퓨터로 비교적 쉽게 구현할 수 있기 때문이다.
추가적으로,
데이터 양이 매우 큰 경우 gradient descent와 같은 iterative 한 방법을 통해 해를 구하면 계산량 측면에서 더 효율적으로 해를 구할 수 있다.
1. Gradient descent 방법의 직관적 이해
자신이 한치앞도 잘 안 보이는 울창한 밀림에 있을 때 산 정상으로 가기 위한 방법은 간단합니다. 비록 실제 산 정상이 어디에 있는지는 모르지만 현재 위치에서 가장 경사가 가파른 방향으로 산을 오르다 보면 언젠가는 산 정상에 다다르게 될 것입니다.
또는 이와 반대로 깊은 골짜기를 찾고 싶을 때에는 가장 가파른 내리막 방향으로 산을 내려가면 될 것입니다.
이와 같이 어떤 함수의 극대점을 찾기 위해 현재 위치에서의 gradient 방향으로 이동해 가는 방법을gradient ascent 방법, 극소점을 찾기 위해 gradient 반대 방향으로 이동해 가는 방법을gradient descent 방법이라 부릅니다. ( 이와 같은 설명들이 러프하게는 실제 딥러닝에서 가중치들의 최적의 해를 찾아가는 가장 기본적인 방법이라고 생각하시면 될 것 같습니다.)
2. Gradient(그레디언트)
기울기(gradient그레이디언트) 또는 경도란 벡터 미적분학에서 스칼라장의 최대의 증가율을 나타내는 벡터장을 뜻한다. 쉽게 말해서 미분해서 나온 결과 값 또는 딥러닝의 수학적으로는 텐서 연산의 변화율이다. 이는 다차원 입력, 즉 텐서를 입력으로 받는 함수에 변화율 개념을 확장시킨 것이라고 생각하시면 될 것 같습니다.
어떤 다변수 함수 f(x1,x2,...,xn)이 있을 때, f의 그레디언트(gradient)는
다변수 함수 (1)
와 같이 정의됩니다. 즉, 그레디언트(gradient)는 위 식과 같이 각 변수로의 일차 편미분 값으로 구성되는 벡터입니다. 그리고 이 벡터는f의 값이 가장 가파르게 증가하는 방향을 나타냅니다. 또한 벡터의 크기는 그 증가의 가파른 정도(기울기)를 나타냅니다.
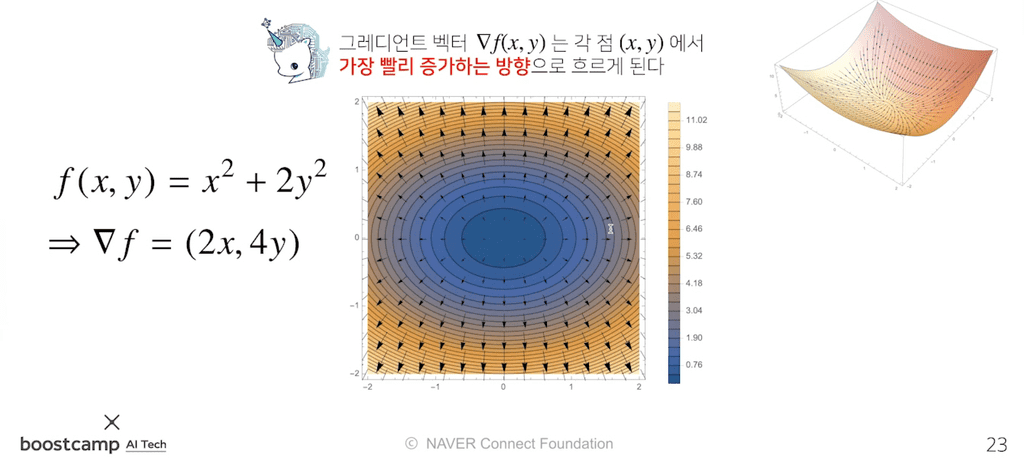
예를 들어, f(x,y) = x2+ y2의 그레디언트(gradient)를 구해보면
다변수 함수 (2)
이므로, (1,1)에서 f값이 최대로 증가하는 방향은 (2,2), 그 기울기는 ∥(2,2)∥= sqrt(8)입니다.
<그림 1> f(x,y) == x^2 + y^2 그래프
또한 반대로 그레디언트(gradient)에 음수를 취하면 즉, -▽f는 f값이 가장 가파르게 감소하는 방향을 나타내게 됩니다.
이러한 그레디언트의 특성은 어떤 함수를 지역적으로 선형 근사(linear approximation)하거나 혹은 함수의 극점(최댓값, 최솟값 지점)을 찾는 용도로 활용될 수 있습니다.
Gradient 벡터
그런데 생각해보자면 딥러닝에서는 입력값이 이차원 공간의 점이 아니라,n차원 공간의 점인 벡터입니다. 그래프를 따라 왼쪽, 오른쪽으로만 이동하는 것이 아니라,n차원이기 때문에 굉장히 많은 방향으로 이동할 수 있을 것입니다. 이 경우 단순한 미분으로는 함수값의 변화을 측정하기 힘든 부분이 있습니다.
따라서 이처럼 벡터가 입력값인 다변수 함수의 경우,편미분(partial differentiation)을 사용합니다.
gradient 벡터−∇f는∇(−f)와 같고, 이는 각 점(x,y)(x,y)에서가장 빨리 감소하는 방향과 같다.
이는 임의의 차원d에서도 성립한다.
3. Gradient descent 방법
최적화 알고리즘 중 하나로 널리 알려진 gradient descent 방법은 이러한 그레디언트의 특성을 이용하여 어떤 비용 함수의 값을 최소화시키기 위한 파라미터 값을 아래와 같이 점진적으로 찾는 방법입니다. 여기서 말하는 '어떤 비용 함수'라 함은 딥러닝에서 사용하는 Cost function을 뜻하며, 다른 말로는 손실 함수, loss function을 뜻 합니다.
식 (3)
즉, 어떤 초기값 x0 = (x10,..., xn0)부터 시작하여 위 식에 따라 gradient 반대 방향으로 x를 조금씩 이동시키면 f(x)가 극소가 되는x를 찾을 수 있다는 방법이 gradient descent 방법입니다.
☞ 만일 함수의 극소점이 아니라 극대점을 찾는 것이 목적이라면 식 (3) 대신에 아래의 식 (4)를 이용하여x를 업데이트합니다 (gradient ascent 방법)
식 (4)<그림 2> gradient descent 방법 (그림출처: 위키피디아)
식 (3)에서 λ는 알고리즘의 수렴 속도를 조절하는 파라미터로서 step size 또는 learning rate라 불립니다.
Gradient descent 방법의 문제점은 쉽게 생각할 수 있듯이 local minimum에 빠지는 것입니다. 즉, 이쪽이 산 정상인 줄 알고 열심히 올라갔더니 막상 여기는 작은 언덕 정도이고 바로 옆에 훨씬 높은 산이 있는 경우입니다.
Gradient descent 방법의 또 하나의 문제점은 해에 근접할수록 |∇f|가 0에 가까워지기 때문에 수렴 속도가 느려진다는 것입니다. 그렇다고 수렴 속도를 조절하는 step size 파라미터 λ를 너무 크게 하면 알고리즘이 발산할 수 있는 문제점이 있습니다 (step size를 자동으로 adaptive 하게 조절하는 방법도 있습니다).
4. gradient descent의 수식 유도
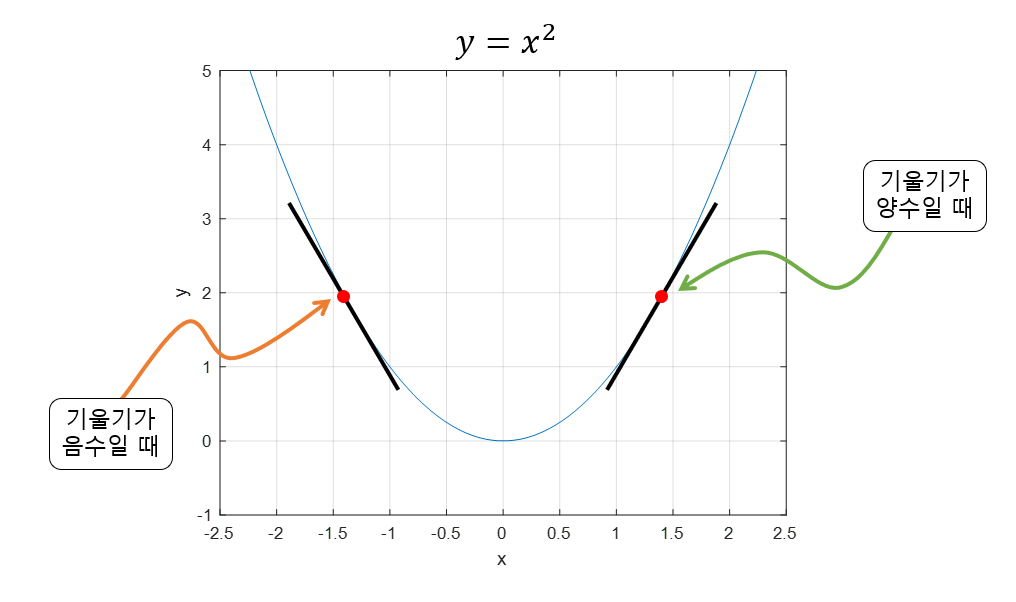
앞서서 이야기한 '어떤 비용 함수의 값을 최소화시키기 위한 파라미터 값을 아래와 같이 점진적으로 찾는 방법'인 gradient descent는 함수의 기울기(즉, gradient)를 이용해x의 값을 어디로 옮겼을 때 함수가 최솟값을 찾는지 알아보는 방법이라고 할 수 있습니다. 기울기가 양수라는 것은x값이 커질수록 함수 값이 커진다는 것을 의미하고, 반대로 기울기가 음수라면x값이 커질 수록 함수의 값이 작아진다는 것을 의미한다고 볼 수 있습니다. ( 여기서 우리가 찾는 것은 손실 함수의 최솟값을 얼마나 잘 찾는 것이 목표가 됩니다.)
또, 기울기의 값이 크다는 것은 가파르다는 것을 의미하기도 하지만, 또 한편으로는(일반적으로) x의 위치가 최솟값/최댓값에 해당되는x좌표로부터 멀리 떨어져 있는 것을 의미하기도 합니다.
<그림 3> 기울기가 양수일 때와 음수일 때의 비교
위에서 간단하게만 설명했으니 이제 선형회귀를 예로 들면서 설명해보도록 하겠습니다.
풀이
선형회귀의 목적식 (5)
선형회귀의 목적은 이를 최소화하는β를 찾는 것이다. 따라서 목적식을β로 미분한다음, 주어진β에서 미분값을 뺀다면, 경사하강법 알고리즘으로 최소에 해당하는 점을 구할 수 있다.
선형회귀 행렬 X에 m개의 변수와 n개의 샘플이 있고, 각 샘플에 대한 결과값인 y가 있는 상태를 가정하자 이때, Xβ=^y≈yXβ=y^≈y 를 만족하는 β를 찾고자 하는 것이 선형회귀분석이다. 하지만 어떤 β으로도 Xβ=yXβ=y를 만족시키는 건 거의 불가능하므로 목적함수를 설정하는데, 이는 y−^y의 L2 Norm을 최소화하는 것으로 한다.
minβ||y−^y||2minβ||y−y^||2 즉, ||y−^y||2||y−y^||2 를 최소화하는 β를 구하는 것이 목표이다.
다음과 같은 Grdient 벡터를 구해보자.
β=(β1,β2,⋯,βd)
이 때β의 k번째 계수에 해당하는βk를 가지고 목적식을 편미분하는 식을 풀어서 보면 아래와 같은 식이 됩니다.
여기서 조심할 점은,일반적인 수학의L_2 - norm과 풀이 방식이 살짝 다르다는 것입니다.
여기서 사용하는L_2-norm은 모델 학습에 사용되는 것이므로, n개의 데이터셋을 가지고 있다는 가정하에 출발합니다. 따라서 단순히 바로 합산해서 루트를 씌워주는 합산식을 쓸게 아니라 먼저 1/n으로 평균을 내준뒤에 사용하셔야 합니다.
이 때에 사용되는 loss(cost fuction)는RMSE(Root Mean Squared Error)입니다. 다음과 같은 도출과정을 따르고 있습니다.
SE(Sqaured Error)는 각 데이터별로 정답과 예측 벡터의 차이를L_2-norm의 제곱으로 계산한다.
MSE (Mean Squared Error)는SE를 데이터의 숫자만큼 나누어준다.(평균내기)
RMSE (Root Mean Squared Error)는MSE에 제곱근을 취해준다.
사실 정확히 쓰면 기대값 기호를 붙여
식 (6)
라고 써야하지만, norm의 기호가 원래 확장성이 있기도 하고, 관용적으로RSME를L_2-norm처럼 쓴다고 합니다.
이를 계산하여 정리하면 다음과 같습니다.
식 (7)
식 (8)
식 8번을 최소화하면 식이 좀 더 간결해진다.
경사하강법의 한계
위의 알고리즘은 다음과 같은 이유로 모든 상황에서 작동하지는 않는다.
이론적으로 경사하강법을 사용하려면 목적함수가 모든 지점에서 미분 가능해야하며, 볼록한(convex) 형태를 가져야 한다.
선형회귀의 경우 목적식∥y−Xβ∥2은 회귀계수β에 대해 볼록함수이므로 알고리즘을 충분히 돌리면 수렴이 보장된다.
하지만 비선형회귀 문제의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지 않는다.
Learning Rate 값이 너무 작거나 커서 지역적인 극소 위치로 수렴할 경우 전체 목적식에 대한 최솟값을 보장하지 못한다.
Computer Vision과 달리 NLP에서 텍스트 자체를 바로 피처로 사용할 수는 없습니다. 사전에 텍스트 전처리 작업이 반드시 필요합니다. 텍스트 전처리를 위해서는 토큰화(tokenization) & 정제(cleaning) & 정규화(normalization)하는 일을 하게 됩니다. 이번에는 그중에서도 토큰화에 대해서 알아보도록 하겠습니다.
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 합니다. 그럼 먼저 말뭉치(Corpus, 코퍼스)의 뜻에 대해 먼저 알아보면
말뭉치또는코퍼스(영어:corpus,복수형:corpora)는 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다. 컴퓨터의 발달로 말뭉치 분석이 용이해졌으며 분석의 정확성을 위해 해당 자연언어를형태소 분석하는 경우가 많다. 확률/통계적 기법과 시계열적인 접근으로 전체를 파악한다. 언어의 빈도와 분포를 확인할 수 있는 자료이며, 현대 언어학 연구에 필수적인 자료이다. 인문학에 자연과학적 방법론이 가장 성공적으로 적용된 경우로 볼 수 있다.
토큰(Token)이란 문법적으로 더 이상 나눌 수 없는 언어 요소를 뜻합니다. 텍스트 토큰화(Text Tokenization)란 말뭉치로부터 토큰을 분리하는 작업을 뜻합니다.
예를 들어, 아이유의 노래 Love poem의 가사 중 "Here i am"이라는 말뭉치를 토큰화 한다고 가정하면 "Here", "i", "am" 이런 식으로 나뉘게 될 겁니다.(이상적인 경우)
텍스트 토큰화의 유형은 문장 토큰화와 단어 토큰화로 나눌 수 있습니다. 문장 토큰화는 텍스트에서 문장을 분리하는 작업을 뜻하고, 단어 토큰화는 문장에서 단어를 토큰으로 분리하는 작업을 뜻합니다.
문장 토큰화(Sentence Tokenization)
문장 토큰화는 문장의 마침표(.), 개행문자(\n), 느낌표(!), 물음표(?) 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것이 일반적입니다. 하지만 꼭 그렇지는 않습니다. 예를 들어, "Hello! I'm a Ph.D student."라는 텍스트를 문장 토큰화를 진행 할 경우 "Hello", "I'm a ph.D student"로 2개의 문장으로 분리를 해야 하는데, 마침표(.)를 기준으로 문장 토큰화를 하면 "Hello", "I'm a ph", "D student"로 3개의 문장으로 엉터리로 분리하게 됩니다. 따라서 100% 정확하게 문장을 분리하는 것은 쉬운 일이 아닙니다.
from nltk.tokenize import sent_tokenize
text = "His barber kept his word. But keeping such a huge secret to himself was driving him crazy. Finally, the barber went up a mountain and almost to the edge of a cliff. He dug a hole in the midst of some reeds. He looked about, to make sure no one was near."
print('문장 토큰화1 :',sent_tokenize(text))
['His barber kept his word.', 'But keeping such a huge secret to himself was driving him crazy.', 'Finally, the barber went up a mountain and almost to the edge of a cliff.', 'He dug a hole in the midst of some reeds.', 'He looked about, to make sure no one was near.']
3개의 문장이 잘 분류가 되고 있는 것을 확인할 수 있습니다. 위의 3 문장의 경우 단순히 마침표만으로 구분해도 구분할 수 있는 문장인데요. 중간에 마침표로 사용되지 않는 Ph.D가 포함된 문장도 토큰화를 진행해보도록 하겠습니다.
text_sample = 'I am actively looking for Ph.D. students. and you are a Ph.D student.'
tokenized_sentences = sent_tokenize(text_sample)
print('Ph.D.가 포함된 문장 토큰화 :',sent_tokenize(text_sample))
Ph.D.가 포함된 문장 토큰화 : ['I am actively looking for Ph.D. students.', 'and you are a Ph.D student.']
마침표(.)를 기준으로 분리하지 않았기 때문에 정확히 분리된 것을 볼 수 있습니다.
단어 토큰화 (Word Tokenization)
단어 토큰화는 기본적으로 띄어쓰기를 기준으로 합니다. 영어는 보통 띄어쓰기로 토큰이 구분되는 반면, 한국어는 띄어쓰기 만으로 토큰을 구분하기는 어렵습니다. 심지어 띄어쓰기가 잘못되어 있는 경우도 허다하고요. 우선은 영어를 기반으로 실습해보겠습니다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print('단어 토큰화1 :',word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
결과를 보시면 띄어쓰기를 기반으로 분리를 하되 콤마(,)와 마침표(.)는 별도의 토큰으로 구분했습니다. 어퍼스트로피(')가 있는 경우 Don't는 Do와 n't로 Jone's는 Jone'과 's로 구분했습니다.
마지막으로 nltk가 아닌 keras의 text_to_word_sequence로 실습해보겠습니다.
from keras.preprocessing.text import text_to_word_sequence
sentence = "Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."
words = text_to_word_sequence(sentence)
print("keras_text_to_word_sequence : ",words)
keras의 text_to_word_sequence는 모든 알파벳을 소문자로 바꾸고, 구두점(컴마, 마침표 등)을 없애고, 어퍼스트로피(')도 보존하여 토큰을 제대로 구분해준 것을 볼 수 있습니다.(성능이 괜찮네요)
문장 토큰화와 단어 토큰화 모두 정규 표현식을 활용하여 토큰화하는 작업도 가능합니다.(정규화를 쓸 경우에는 정교하게 진행해야 제공되는 api이상 혹은 비슷한 성능이 나올 겁니다.) 문장 토큰화는 문장 자체가 중요한 의미를 가질 경우 사용되며, 일반적으로는 단어 토큰화만 사용해도 충분합니다.
영어는 해봤으니 앞으로 사용할 한국어의 경우에는 박상길님이 개발한 KSS(Korean Sentence Splitter)를 '딥러닝을 이용한 자연어 처리 입문'에서 추천하고 있습니다. KSS를 설치합니다.
pip install kss
KSS를 통해서 문장 토큰화를 진행해보겠습니다.
import kss
text = '아이유의 2022년도 콘서트 이름은 골든아워입니다. 저번주 주말에 갔는데 팬들에게 방석을 나눠주더라구요. 저는 연두색 방석을 받았습니다.'
print('한국어 문장 토큰화 :',kss.split_sentences(text))
한국어 문장 토큰화 : ['아이유의 2022년도 콘서트 이름은 골든아워입니다.', '저번주 주말에 갔는데 팬들에게 방석을 나눠주더라구요.', '저는 연두색 방석을 받았습니다.']
출력 결과는 정상적으로 모든 문장이 분리된 결과를 보여줍니다. (조금 애매한 문장을 잘 안나뉘는 케이스들도 있습니다. 참고하시기 바래요.)
한국어에서의 토큰화의 어려움
영어는 New York과 같은 합성어나 he's 와 같이 줄임말에 대한 예외처리만 한다면, 띄어쓰기(whitespace)를 기준으로 하는 띄어쓰기 토큰화를 수행해도 단어 토큰화가 잘 작동합니다. 거의 대부분의 경우에서 단어 단위로 띄어쓰기가 이루어지기 때문에 띄어쓰기 토큰화와 단어 토큰화가 거의 같기 때문입니다.
하지만 한국어는 영어와는 달리 띄어쓰기만으로는 토큰화를 하기에 부족합니다. 한국어의 경우에는 띄어쓰기 단위가 되는 단위를 '어절'이라고 하는데 어절 토큰화는 한국어 NLP에서 지양되고 있습니다. 어절 토큰화와 단어 토큰화는 같지 않기 때문입니다. 그 근본적인 이유는 한국어가 영어와는 다른 형태를 가지는 언어인 교착어라는 점에서 기인합니다. 교착어란 조사, 어미 등을 붙여서 말을 만드는 언어를 말합니다.
1) 교착어의 특성
예를 들어봅시다. 영어와는 달리 한국어에는 조사라는 것이 존재합니다. 예를 들어 한국어에 그(he/him)라는 주어나 목적어가 들어간 문장이 있다고 합시다. 이 경우, 그라는 단어 하나에도 '그가', '그에게', '그를', '그와', '그는'과 같이다양한 조사가 '그'라는 글자 뒤에 띄어쓰기 없이 바로 붙게됩니다. 자연어 처리를 하다보면 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식이 되면 자연어 처리가 힘들고 번거로워지는 경우가 많습니다. 대부분의 한국어 NLP에서 조사는 분리해줄 필요가 있습니다.
띄어쓰기 단위가 영어처럼 독립적인 단어라면 띄어쓰기 단위로 토큰화를 하면 되겠지만 한국어는 어절이 독립적인 단어로 구성되는 것이 아니라 조사 등의 무언가가 붙어있는 경우가 많아서 이를 전부 분리해줘야 한다는 의미입니다.
한국어 토큰화에서는형태소(morpheme)란 개념을 반드시 이해해야 합니다. 형태소(morpheme)란 뜻을 가진 가장 작은 말의 단위를 말합니다. 이 형태소에는 두 가지 형태소가 있는데 자립 형태소와 의존 형태소입니다.
자립 형태소: 접사, 어미, 조사와 상관없이 자립하여 사용할 수 있는 형태소. 그 자체로 단어가 된다. 체언(명사, 대명사, 수사), 수식언(관형사, 부사), 감탄사 등이 있다.
의존 형태소: 다른 형태소와 결합하여 사용되는 형태소. 접사, 어미, 조사, 어간를 말한다.
예를 들어 다음과 같은 문장이 있다고 합시다.
문장 : 에디가 책을 읽었다
이 문장을 띄어쓰기 단위 토큰화를 수행한다면 다음과 같은 결과를 얻습니다.
['에디가', '책을', '읽었다']
하지만 이를 형태소 단위로 분해하면 다음과 같습니다.
자립 형태소 : 에디, 책 의존 형태소 : -가, -을, 읽-, -었, -다
'에디'라는 사람 이름과 '책'이라는 명사를 얻어낼 수 있습니다. 이를 통해 유추할 수 있는 것은 한국어에서 영어에서의 단어 토큰화와 유사한 형태를 얻으려면 어절 토큰화가 아니라 형태소 토큰화를 수행해야한다는 겁니다.
2) 한국어는 띄어쓰기가 영어보다 잘 지켜지지 않는다.
사용하는 한국어 코퍼스가 뉴스 기사와 같이 띄어쓰기를 철저하게 지키려고 노력하는 글이라면 좋겠지만, 많은 경우에 띄어쓰기가 틀렸거나 지켜지지 않는 코퍼스가 많습니다.
한국어는 영어권 언어와 비교하여 띄어쓰기가 어렵고 잘 지켜지지 않는 경향이 있습니다. 그 이유는 여러 견해가 있으나, 가장 기본적인 견해는 한국어의 경우 띄어쓰기가 지켜지지 않아도 글을 쉽게 이해할 수 있는 언어라는 점입니다. 띄어쓰기가 없던 한국어에 띄어쓰기가 보편화된 것도 근대(1933년, 한글맞춤법통일안)의 일입니다. 띄어쓰기를 전혀 하지 않은 한국어와 영어 두 가지 경우를 봅시다.
EX1) 제가이렇게띄어쓰기를전혀하지않고글을썼다고하더라도글을이해할수있습니다.
EX2) Tobeornottobethatisthequestion
영어의 경우에는 띄어쓰기를 하지 않으면 손쉽게 알아보기 어려운 문장들이 생깁니다. 이는 한국어(모아쓰기 방식)와 영어(풀어쓰기 방식)라는 언어적 특성의 차이에 기인합니다. 이 책에서는 모아쓰기와 풀어쓰기에 대한 설명은 하지 않겠습니다. 다만, 결론적으로 한국어는 수많은 코퍼스에서 띄어쓰기가 무시되는 경우가 많아 자연어 처리가 어려워졌다는 것입니다.
품사 태깅(Part-of-speech tagging)
단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기도 합니다. 예를 들어서 영어 단어 'fly'는 동사로는 '날다'라는 의미를 갖지만, 명사로는 '파리'라는 의미를 갖고있습니다. 한국어도 마찬가지입니다. '못'이라는 단어는 명사로서는 망치를 사용해서 목재 따위를 고정하는 물건을 의미합니다. 하지만 부사로서의 '못'은 '먹는다', '달린다'와 같은 동작 동사를 할 수 없다는 의미로 쓰입니다. 결국 단어의 의미를 제대로 파악하기 위해서는 해당 단어가 어떤 품사로 쓰였는지 보는 것이 주요 지표가 될 수도 있습니다. 그에 따라 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분해놓기도 하는데, 이 작업을 품사 태깅(part-of-speech tagging)이라고 합니다. NLTK와 KoNLPy를 통해 품사 태깅 실습을 진행합니다.
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
print('단어 토큰화 :',tokenized_sentence)
print('품사 태깅 :',pos_tag(tokenized_sentence))
한국어 자연어 처리를 위해서는 KoNLPy(코엔엘파이)라는 파이썬 패키지를 사용할 수 있습니다. 코엔엘파이를 통해서 사용할 수 있는 형태소 분석기로 Okt(Open Korea Text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)가 있습니다.
한국어 NLP에서 형태소 분석기를 사용하여 단어 토큰화. 더 정확히는 형태소 토큰화(morpheme tokenization)를 수행해보겠습니다. 여기서는 Okt와 꼬꼬마 두 개의 형태소 분석기를 사용하여 토큰화를 수행하겠습니다.
데이터를 수집하고 머신 러닝을 하는 과정을 크게 6가지로 나누면, 아래의 그림과 같습니다. (나누는 과정은 Task별로 조금 달라 질 수 있습니다.)
1) 수집(Acquisition)
머신 러닝을 하기 위해서는 기계에 학습시켜야 할 데이터가 필요합니다. 자연어 처리의 경우, 자연어 데이터를말뭉치 또는 코퍼스(corpus)라고 부르는데 코퍼스의 의미를 풀이하면, 조사나 연구 목적에 의해서 특정 도메인으로부터 수집된 텍스트 집합을 말합니다. 텍스트 데이터의 파일 형식은 txt 파일, csv 파일, xml 파일 등 다양하며 그 출처도 음성 데이터, 웹 수집기를 통해 수집된 데이터, 영화 리뷰 등 다양합니다.
2) 점검 및 탐색(Inspection and exploration)
데이터가 수집되었다면, 이제 데이터를 점검하고 탐색하는 단계입니다. 여기서는 데이터의 구조, 노이즈 데이터, 머신 러닝 적용을 위해서 데이터를 어떻게 정제해야하는지 등을 파악해야 합니다.
이 단계를탐색적 데이터 분석(Exploratory Data Analysis, EDA) 단계라고도 하는데 이는 독립 변수, 종속 변수, 변수 유형, 변수의 데이터 타입 등을 점검하며 데이터의 특징과 내재하는 구조적 관계를 알아내는 과정을 의미합니다. 이 과정에서 시각화와 간단한 통계 테스트를 진행하기도 합니다.
3) 전처리 및 정제(Preprocessing and Cleaning)
데이터에 대한 파악이 끝났다면, 머신 러닝 워크플로우에서 가장 까다로운 작업 중 하나인 데이터 전처리 과정에 들어갑니다. 이 단계는 많은 단계를 포함하고 있는데, 가령 자연어 처리라면 토큰화, 정제, 정규화, 불용어 제거 등의 단계를 포함합니다. 빠르고 정확한 데이터 전처리를 하기 위해서는 사용하고 있는 툴(이 책에서는 파이썬)에 대한 다양한 라이브러리에 대한 지식이 필요합니다. 정말 까다로운 전처리의 경우에는 전처리 과정에서 머신 러닝이 사용되기도 합니다.
4) 모델링 및 훈련(Modeling and Training)
데이터 전처리가 끝났다면, 머신 러닝에 대한 코드를 작성하는 단계인 모델링 단계에 들어갑니다. 적절한 머신 러닝 알고리즘을 선택하여 모델링이 끝났다면, 전처리가 완료 된 데이터를 머신 러닝 알고리즘을 통해 기계에게 학습(training)시킵니다. 이를 훈련이라고도 하는데, 이 두 용어를 혼용해서 사용합니다. 기계가 데이터에 대한 학습을 마치고나서 훈련이 제대로 되었다면 그 후에 기계는 우리가 원하는 태스크(task)인 기계 번역, 음성 인식, 텍스트 분류 등의 자연어 처리 작업을 수행할 수 있게 됩니다.
여기서 주의해야 할 점은 대부분의 경우에서 모든 데이터를 기계에게 학습시켜서는 안 된다는 점입니다. 뒤의 실습에서 보게되겠지만 데이터 중 일부는 테스트용으로 남겨두고 훈련용 데이터만 훈련에 사용해야 합니다. 그래야만 기계가 학습을 하고나서, 테스트용 데이터를 통해서 현재 성능이 얼마나 되는지를 측정할 수 있으며 과적합(overfitting) 상황을 막을 수 있습니다. 사실 최선은 훈련용, 테스트용으로 두 가지만 나누는 것보다는 훈련용, 검증용, 테스트용. 데이터를 이렇게 세 가지로 나누고 훈련용 데이터만 훈련에 사용하는 것입니다.
검증용과 테스트용의 차이는 무엇일까요? 수능 시험에 비유하자면 훈련용은 학습지, 검증용은 모의고사, 테스트용은 수능 시험이라고 볼 수 있습니다. 학습지를 풀고 수능 시험을 볼 수도 있겠지만, 모의 고사를 풀며 부족한 부분이 무엇인지 검증하고 보완하는 단계를 하나 더 놓는 방법도 있겠지요. 사실 현업의 경우라면 검증용 데이터는 거의 필수적입니다.
검증용 데이터는 현재 모델의 성능. 즉, 기계가 훈련용 데이터로 얼마나 제대로 학습이 되었는지를 판단하는 용으로 사용되며 검증용 데이터를 사용하여 모델의 성능을 개선하는데 사용됩니다. 테스트용 데이터는 모델의 최종 성능을 평가하는 데이터로 모델의 성능을 개선하는 일에 사용되는 것이 아니라, 모델의 성능을 수치화하여 평가하기 위해 사용됩니다. 쉽게 말해 시험에 비유하면 채점하는 단계입니다. 따라서 Test셋의 경우
이 책에서는 실습 상황에 따라서 훈련용, 검증용, 테스트용 세 가지를 모두 사용하거나 때로는 훈련용, 테스트용 두 가지만 사용하기도 합니다. 하지만 현업에서 최선은 검증용 데이터 또한 사용하는 것임을 기억해둡시다.
5) 평가(Evaluation)
미리 언급하였는데, 기계가 다 학습이 되었다면 테스트용 데이터로 성능을 평가하게 됩니다. 평가 방법은 기계가 예측한 데이터가 테스트용 데이터의 실제 정답과 얼마나 가까운지를 측정합니다.
6) 배포(Deployment)
평가 단계에서 기계가 성공적으로 훈련이 된 것으로 판단된다면 완성된 모델이 배포되는 단계가 됩니다. 다만, 여기서 완성된 모델에 대한 전체적인 피드백으로 인해 모델을 업데이트 해야하는 상황이 온다면 수집 단계로 돌아갈 수 있습니다.
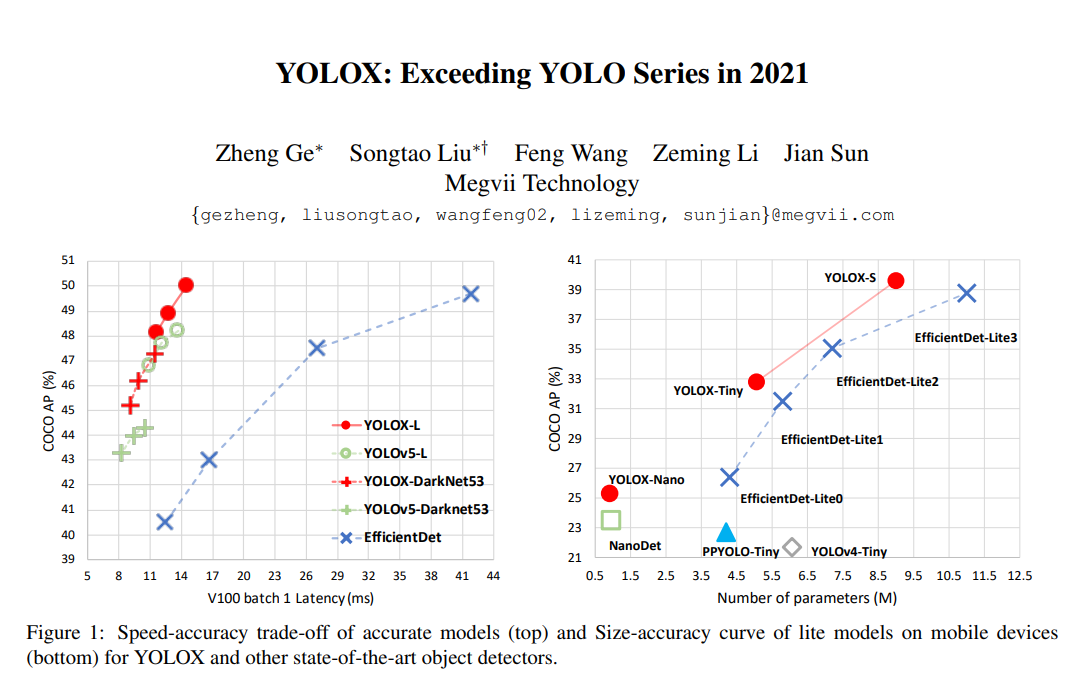
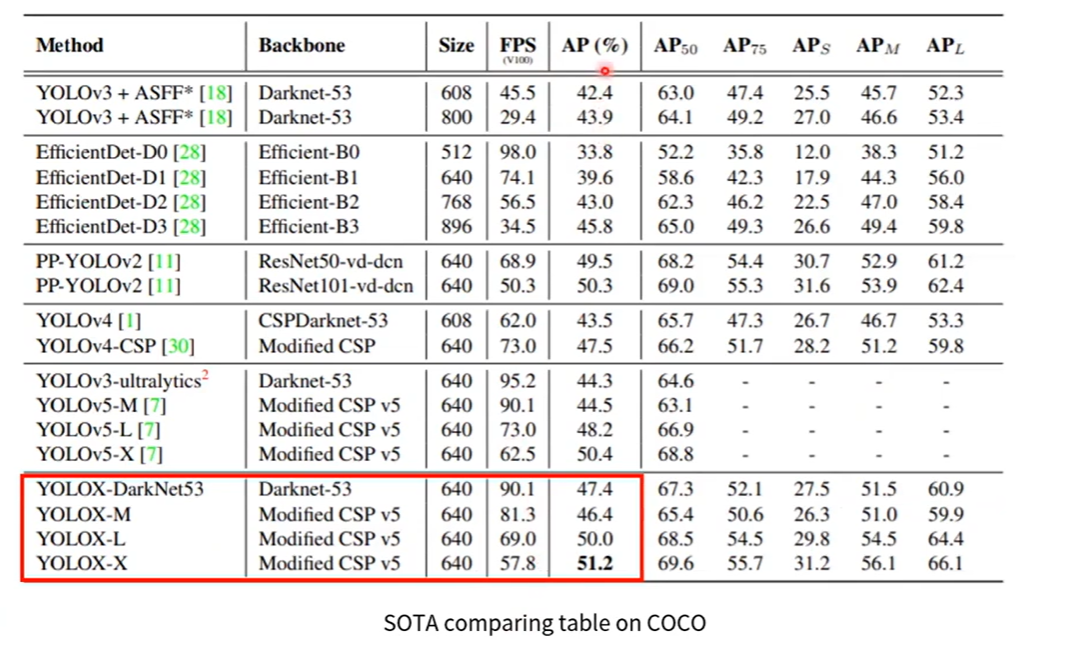
왼쪽 그래프의 성능을 보게 되면 SOTA 모델인 EfficientDet 모델보다 성능이 월등히 높게 나온것을 알 수 있습니다.
(먼저 간단하게 YOLO의 역사에 대해서 언급하고 시작하겠습니다.)
2개의 branch로 나눈 다음에
1. Introduction / brief history of YOLO
- YOLO(You Only Look Once)는 이미지 전체를 한번에 처리하는 Object Detection의 대표적인 1-Stage Approach - Real-time Object Detection으로 큰 주목 - 그 후 해를 거듭하며 발전 ( YOLOv1, v2, v3, v4, v5, PP-YOLO, ... ) - 최근에 트랜스포머 계열의 모델들이 Object Detection 태스크에 들어오기 전에는 대부분의 Object Detection 모델들은 CNN개반으로 수행했는데, 이번에 다루는 YOLO 역시 대표적인 CNN 기반의 네트워크
오른쪽에 보시면 citation수를 나타내고 있는데, 이는 YOLO 시리즈 모델들이 얼마나 널리 쓰이고 있는가에 대한 반증이기도 합니다.
해당 모델이 어떻게 발전했는지를 간단하게만 소개해 드리자면,
한번에 바운딩 박스를 그리고 물체를 분류하는 YOLOv1이 제안
.미리 정해둔 형태의 박스를 바운딩 박스의 후보로 사용하는 anchor 박스 개념을 제안
작은 물체도 탐지가 가능한 모델 아이디어를 제안
1. Introduction / YOLOX Overview
- 최근 2년동안 연구자들은 Anchor-Free Detector, Advanced Label Assignment Strategy, End-to-end Detector의 연구에 주목하였지만 YOLO 시리즈에는 적용되지 않음 - 따라서 본 논문에서는 그러한 좋은 기법들을 적용하여 성능 개선에 목적을 두었다.
Key concepts
Anchor-free 방식의 Yolo구조
Object Detection을 위한 발전 기술 적용 :
Decoupled head ( head를 분리 )
발전된 Label assignment 기법 적용 : SimOTA
강력한 data augmentation : Mosaic, Mixup
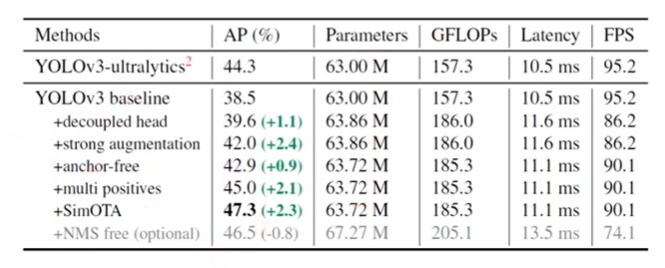
YOLOv3 baseline
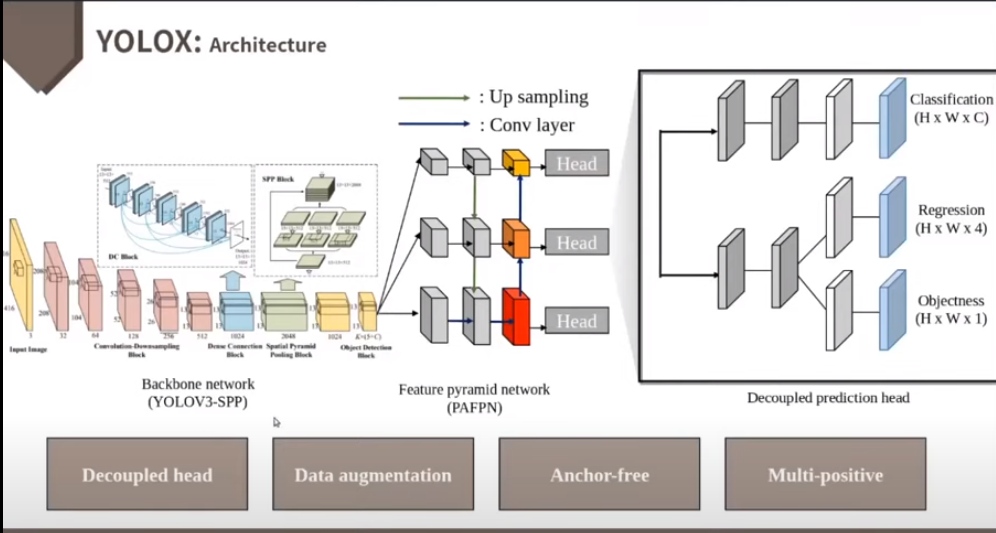
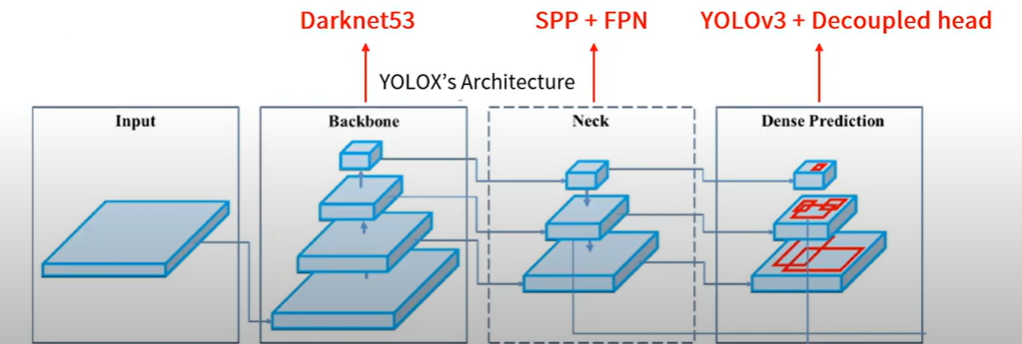
YOLOv4, v5가 anchor-based 파이프라인에 과도하게 최적화 될 수 있음을 고려하여 YOLOv3-SPP를 base architecture로 선정
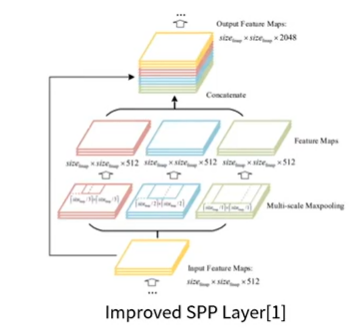
- 먼저 Backbone인 DarkNet에서 feature map을 추출합니다. - Neck에서는 위에 그림과 같이 공간구조의 정보를 유지는 SPP Layer를 사용합니다. ( 이와 관련된 내용은 추후 추가적으로 다룰 예정) - 그리고 FPN을 통해 멀티 스케일 Feature map을 얻을 수 있습니다. - Feature에 대한 성숙도가 낮은 아래의 Feature map의 문제를 개선할 수 있는데요. high level의 extraction 정보를 더함으로써 아래의 Feature map이 지니고 있는 위치정보를 같이 활용할 수 있습니다. - Dense Prediction을 보게 되면 위에서부터 큰 물체, 중간 물체, 작은 물체 순으로 detection하는 feature map
2. Network Design / Anchor-free
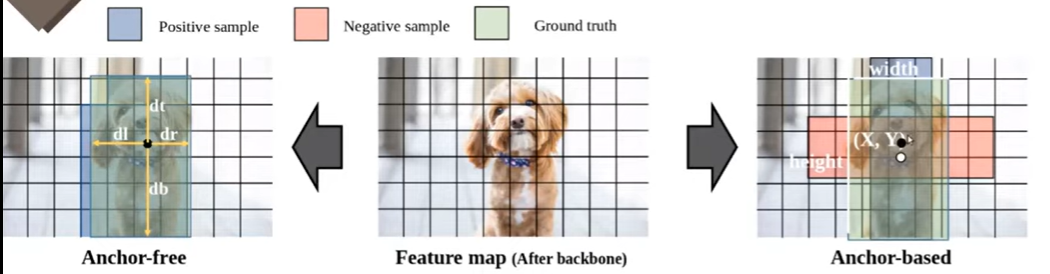
가운데 그림이 Backbon network를 거친 최종 피쳐맵을 의미합니다, 좌측의 경우 Anchor-free 우측의 경우가 Anchor-based 방법을 나타내고 있습니다.
Anchor-based
위의 그림을 보게 되시면 검은 점에서 prediction을 진행한다고 가정을 했을 때, 해당 Cell에서 Regression을 진행 후 나온 output값을 바탕으로 Anchor의 중심점과 가로와 세로의 길이를 결과적으로 bounding box의 가로 세로 길이와 중심점을 학습한다고 보시면 됩니다. ( 이는 네트워크마다 조금씩 다를 순 있습니다.) 여기서 예시를 보게 되면 하나의 Anchor box가 빨간색 박스와 파란색 박스를 만들었다는 걸 의미합니다. 여기서는 초로색 GT box와 초록색 box의 iou값이 높기 때문에 파란색 bounding box가 Positive 샘플로 분류가 됩니다. 빨간색 box는 학습에 참여하지 않음
Anchor-free
위와는 조금 다르게 Anchor-free에서는 GT box안에 있는 Cell들이 전부 Positive 샘플이 됩니다. 예를 들어 위에 그림과 같이 검은 점에서 prediction을 진행 한다고 했을 때, 해당 Cell에서부터 Ground Truth의 각 모서리까지의 길이를 학습하게 됩니다. 이를 바탕으로 Detectiion Task를 수행하게 됩니다.
Anchor-based design의 단점
도메인에 specific해서 다른 데이터에 generalization 어려움 ( 최적의 anchor box 배치가 그 도매인에 specific하게 만듬 ) - ex) 데이터 셋에 따라서 aspect ratio 비율이 달라질 수 있음
Bounding box regression의 범위를 feature level에 따라 pre-define
같은 위치에서 여러 개의 bounding box detect 가능
어떤 point가 예측이 되면 그 point에서 실제 GT의 top,left,right,bottom의 차이를 학습
위의 그림을 추가적으로 설명하자면 YOLOX에서는 같은 포인트에서 두개의 Bounding box를 예측할 수 있는데, 그 이유는 낮은 feature level에서 하나만 예측하도록 ranage를 제한. 즉, feature level에 따라 range가 pre-define
2. Network Design / Architecture
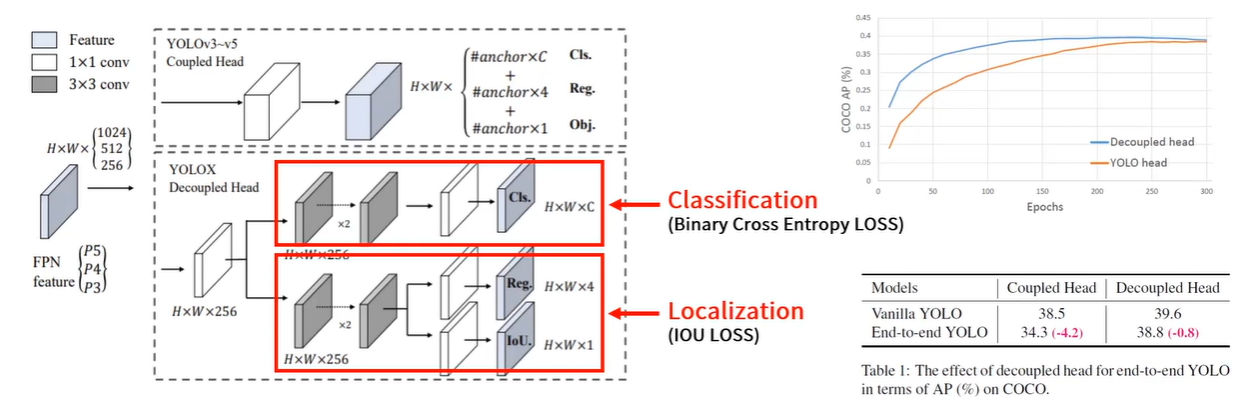
Object detection에서 Classification과 Regression이 서로 상충하는 문제가 존재함[1](아래 논문 참고)
feature map의 결과를 256 Channel로 줄이고 3x3 Conv를 지나는 2개의 branch를 추가
Classification에는 Binary Cross Entropy Loss를 사용해서 각각의 clss에 대한 확률이 나옴
Localization에서는 IOU Loss를 사용하여 Bounding Box에 대한 종횡거리가 나오게 됨
Loclization의 경우 Regression과 Objectness를 포함
Regression Bounding Box에 대한 종횡거리
Objectness의 경우 해당 cell이 백그라운드를 나타내는지 아니면 어떠한 오브젝트라도 포함하는지를 0~1사의 value로 표현
YOLOv3~v5에서 1개였던 기존 head를 분리하면서 수렴 속도와 end-to-end의 AP를 항샹시킴
3. Training Strategies / Strong data augmentation
저자는 여기서 총 4가지의 Data augmentation의 방법을 적용하였습니다. 1. Random horizon flip 2. Color jitter ( 원본 영상의 hsl을 변경하여 증강시키는 클러스터라는 방법 ) 3. Mosaic ( 원본 이미지외에 3개의 추가적인 사진을 섞는 방법 ) 4. Mixup ( 이미지랑 레이블에 다른 거를 조금씩 섞는 방법 ) ( 강력한 Data aumentation을 사용해서 그런지 몰라도 pre-trained weight를 사용해도 성능향상이 별로 일어나지 않아서 scratch 학습을 진행했다고 하는데 일반적인 데이터 셋인 코코 데이터 셋에서 이러한 현상이 발견된 점은 신기합니다. )
3. Training Strategies / Multi-positive
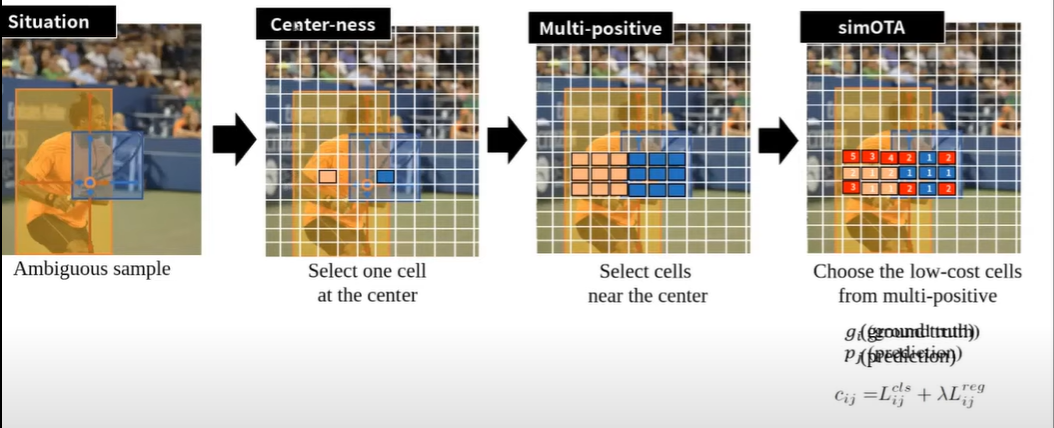
기본적인 Ancor free 방법만으로는 Anchor-based의 정확성을 따라잡기 힘듬에 따라 여러 방법들을 적용하게 됨 1. Center-ness ( FCOS 논문에서 처음 제안) - 위의 사진과 같이 동그라미 점의 cell이 prediction하고자 하는 cell이라면 오브젝트 레이블이 좀 불분명한 점이 있습니다. 이러한 문제 때문에 detection ratio가 떨어진다고 생각해서 FCOS 저자는 positive한 셀들중에서 오브젝트의 중심에 해당하는 셀들만 positive로 할당하는 Center-ness 방법을 사용해서 정확도를 좀 더 항샹 시킴 2. Multi-positive - 중앙에 있는 셀 말고도 그 주위에서도 좋은 prediction을 할 수 있는 셀들을 사용하는 방법. 센터 말고 주위의 셀들도 prediction하는 방법 3. simOTA - 각 cell의 loss를 구해서, 각 Cell에서 Loss가 조금 낮은 애들만 top k를 뽑아서 학습시키는 방법. 예를 들어 그림에서처럼 사람 cell에 해당하는 9개의 sample중에서 5개는 loss가 낮은데 이 낮은 친구들을 positive sample로 사용하자는 의미. 라켓에 해당하는 cell의 경우도 파란색으로 5개가 loss가 낮음 이 친구들을 positive sample로 사용하자!!
4. Experimental results
5. Conclusion
이 논문에서 anchor-free detector를 사용하여 YOLO 시리즈의 업데이트 버전을 제안
최근 고도화된 detection 기술인 decoupled head, advanced label assigning strategy등을 사용해 속도와 정확성이 전반적으로 훌륭한 성능을 보임
전반적으로 널리 쓰이는 YOLOv3의 아키텍쳐를 사용해서 AP(COCO)를 SOTA 최고로 개선시킴
pose estimation : 특정 Pose를 만들어내는 Key-points들을 찾아내는 tast (= "Key-points Localiztion")
Task (Single Person)
1. HPE(Human Pose Estimation )Task의 경우 크게 2D, 3D로 나누어 집니다. ( 여기서는 2D만 다루도록 하겠습니다.) 2. 2D를 크게 Single Person과 Multi Person으로 나눌 수 있습니다. 3. 신체의 머리, 어깨 등의 keypoint를 예측하는 방법으로 Direct Regression 그리고 HeatMap Regression으로 나눌 수 있습니다.
Direct Regression : 2차원 이미지 픽셀 값을 입력으로 이용하여 바로 좌표를 추정하는 방법으로 빠른 학습이 가능합니다. 하지만 사람이 복수로 존재하는 경우 적용하기 어렵고 키포인트 위치가 매우 비선형적이고 적합하게 매핑하기 어렵다는 것이 한계점을 가지고 있습니다.
HeatMap Regression : 신체 부위 중 키포인트가 존재할만한 위치를 확률적으로 HeatMap를 계산하고 HeatMap을 기반으로 키포인트 위치를 추정하는 방법입니다. 보다 시각적으로 직관적이고 동시에 사람이 다수일 경우도 적용이 가능하다고 합니다. ( 대부분 HeatMap 베이스로 예측하는 것이 성능이 훨씬 좋다고 알려져 있습니다.) 따라서 논문 마지막 부분에서도 Heatmap 방식을 적용했다고 합니다.
Task (Multi Person)
1. Multi Person은 Top-down과 Bottom-up 방식으로 나누어 집니다.
Top-down
Top-down 방식은 먼저 사람을 찾고 그 각각의 사람을 대상으로 키포인트 디텍션을 진행하게 됩니다.
왼쪽부터 오른쪽 순서대로 바운딩 박스로 각각의 사람을 디텍션 하게 되고 그 뒤에 바운딩 박스 내에 있는 사람의 키포인트를 찾는 방식
바텀업 방법에 비해 속도가 느리지만 정확도가 높음
Bottom-up
Top-down 방식과 반대로 먼저 모든 키포인트들을 찾은 뒤에 그 각각의 키포인트들을 이어서 각 사람에 맞게끔 연결하는 방법
일반적으로 바텀업 방법이 속도가 빠르지만 정확도가 떨어짐
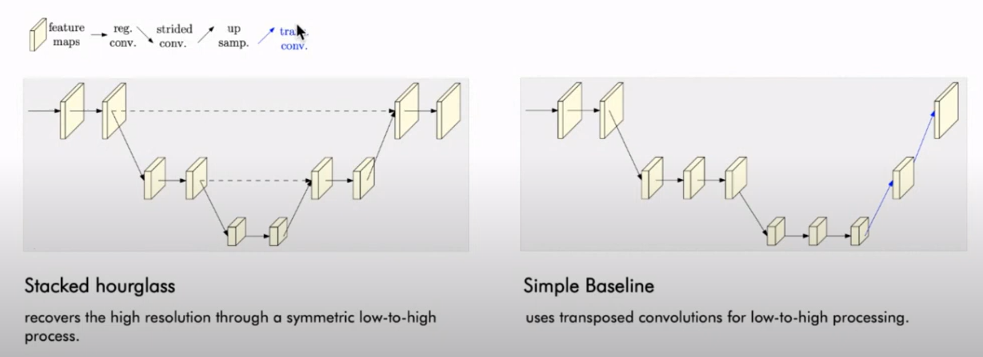
HR-Net에 본격적으로 들어가기 전에 이전 방법들에 대해서 간단하게 설명하도록 하겠습니다.
위의 그림을 보게 되면 대부분 기존 방법들은 이미지를 고해상도에서 저해상도로 압축을 하고 저해상도에서 고해상도로 복원하는 과정을 거칩니다. 그리고 키포인트를 마지막 고해상도에서 찾습니다. 이러한 방법들을 이 논문에서는 직렬적인 시퀀셜한 구조라고 표현합니다. 왼쪽의 모델은 Stacked hourglass 모델로 symmetric하게 high-to-low에서 low-to-high로 진행되는 것을 볼 수 있으며 down sampleing 되기 전에 skip connection이 연결되어 feature 값이 전달되고 있음을 알 수 있습니다. 오른쪽의 모델 Simple Baseline의 경우 Strided Convolution으로 압축을 하고 Upsampling을 하는 과정에서 Transposed Convilution을 적용하게 됩니다. 이러한 직렬적인 구조는 압축하는 과정에서 지엽적인 정보들의 손실을 가져오게 되고 모든 프로세스가 upsampling에 의존하고 있다는 한계점이 있습니다.
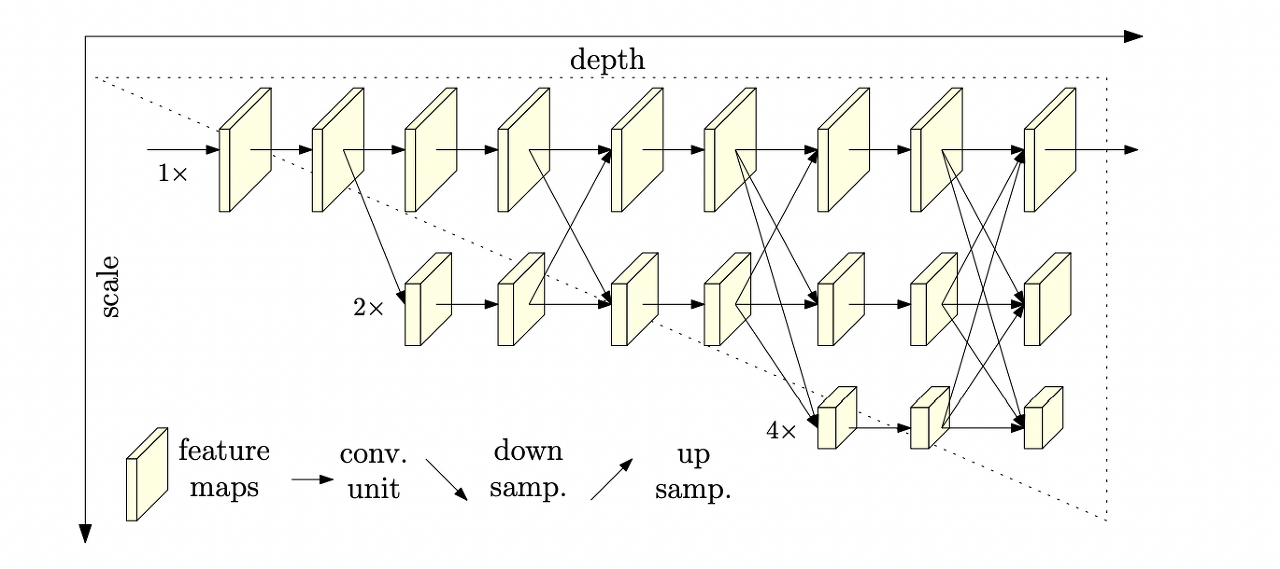
HR Net도 위에 방법들과 기본적으로는 비슷하다. 근본적으로는 scale에 변화를 주면서 다양한 resolution에서 정보를 추출한다. 그럼에도 불구하고 다른 모델들보다 성능이 좋은 이유와 차별성에는 2가지가 있다.
1. High-to-low resolution을Serially(X) Parallel(O)하게 적용한다. 이게 무슨 의미인지는 아래에 나와있다.
기존 : Input받은 strand가 downsample 됨.
HR : Input 받은 strand의 해상도는 쭉 유지가 되고 거기서 평행하게 downsample되는 strand가 분리된다.
이렇게 되면 최종적으로 predicted된 heatmap에 한번도 downsample/upsample되지 않은 input해상도 feature map이 영향을 주기 때문에 훨씬 정확하다.
2.Repeats multi-scale fusions
기존 : 존재하는 대부분의 기법은 low-level and high-level representation을 더한다.
HR : parallel한 sub-network간에 계속 정보를 주고 받는다. (그림을 보면 쉽게 알 수 있음)
같은 depth와 유사한 level의 low-resolution representation을 보조로 사용한다. predicted heatmap도 더 정확한 결과를 보인다.
결과적으로 HRNet의 경우다양한 해상도의 subNet을 병렬적으로 유지함과 동시에exchange unit을 통해서 전체적인 맥락과 국소적인 정보를 지속해서 교환하는 특성이 있다.
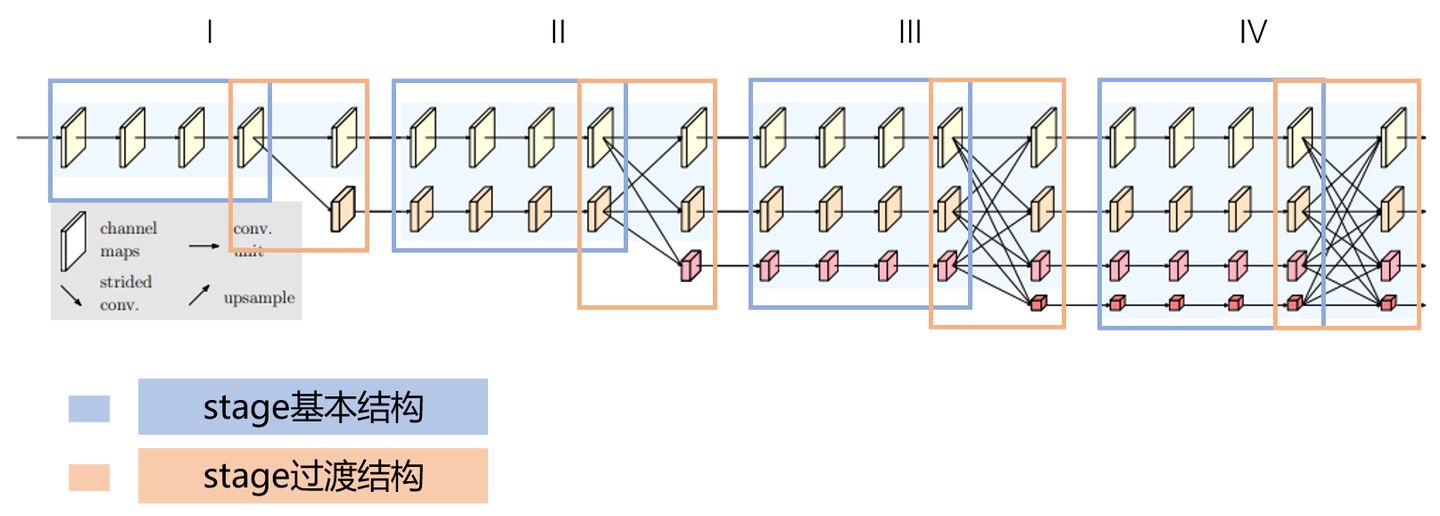
Parallel multi-resolution subnetworks (HR)
NsrNsr에서 앞자리는 stage, r은 downsample된 단계를 의미한다. \
NsrNsr은 첫번째 subnetwork(N11N11)의 해상도의12r−112r−1
high-resolution subnetwork을 처음 stage로 시작한다.
high-to-low resolution subnetworks을 하나씩 추가한다.
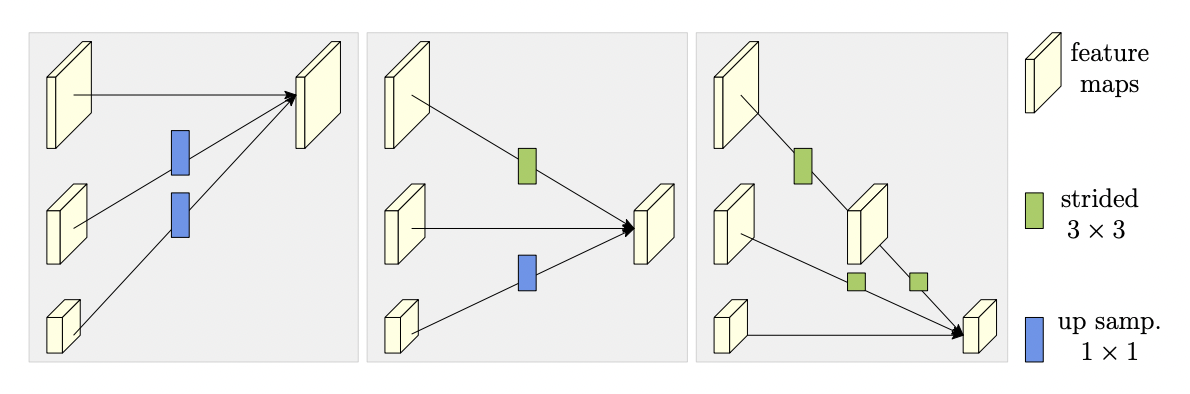
Repeated multi-scale fusion
다양한 scale을 반복적으로 fusion하는 괴정에서 Exchage Unit이란게 사용된다.
Exchange Unit이란 병렬subnetowrk간에 정보를 전달해주는 역할을 하는 유닛이다.
how Exchage unit aggregated info for high, medium and low resolutions
서로 다른 resulution의 정보를 합칠때는 적절하게 upsampling / downsampling이 필요하다.
아래 그림은 stage 3를 여러 exchange block으로 나눈 그래프이다.CbsrCsrb는 r번째 resultion, sth stage, bth block의 convolution unit을 의미한다.
CbsrCsrb에서 s,b를 무시하고 r만 남겨놓는다. (resolution에 따른 차이만 보겠다는 의미)
인공신경망에서 Attention이라고 하는것은 어떤 특정한 신경망을 뜻하는것이 아니라 인간의 시각적 집중(Visual Attention) 현상을 구현하기위한 신경망적 기법을 말합니다.
Attention이 딥러닝 모델 혹은 layer가 아닌 기법인 이유
위의 그림과 같이 구현되어 있다고 가정한다면, 사람이 주목하는 부분에 대해서 고화질을 유지하고 그 이외의 영역에 대해서는 저화질을 유지하게 됩니다. 이 말을 다시 정리하자면, 우리의 초점이 맞는 곳 즉, 우리가 보고자 하는 영역에 대해서는 높은 집중도를 보여서 고화질을 유지하게되고 보지 않는것에 관해서는 낮은 저화질로 낮은 집중도를 유지하게 됩니다. 이러한 현상을 인공신경망에서도 구현을 해보고자 하는것이 Attention 기법이라고 할 수 있겠습니다.
2. 가중치와 어텐션의 공통점과 차이점
가중치도 결국 보고자하는 영역을 집중적으로 본다고 할 수 있는데 그럼 가중치를 학습하는것과 차이는 뭐야?
=> 가중치와 어텐션의 공통점과 차이점
가중치와 어텐션 모두 해당 값을 얼마나 가중시킬 것인가를 나타내는 역활을 하지만, 어텐션을 가중치와 달리 전체 또는 특정 영역의 입력값을 반영하여, 그 중에 어떤 부분에 집중해야 하는지를 나타내는 것을 목표로 한다. ( 어떻게 사용하냐에 따라서 선택적으로 사용할 수 있다는 부분이 다르다고 할 수 있겠다. )
좀 더 상세히 설명하자면 가중치의 경우 <Visual World> 의 이미지가 있다고 가정할 때 각 이미지의 모양, 형태에 집중하는것이 아닌최종적으로 y와 얼마만큼 가까워지게 만들 수 있는지에 focus가 맞춰져 있다고 생각하시면 될 것 같습니다. 또 그 판단기준( y와 유사하게 만드는 값 )에 따라서 가중시킬것인지 축소시킬것인지가 결정됩니다. 하지만 어텐션의 경우 객체나 물체같은 경우를 인식해서 그 객체나 물체가 있는 특정영역만 집중을 하겠다라는게 어텐션의 컨셉이라고 생각하시면 됩니다.
3. 신경망 기계번역
Attention기법이 인공신경망에 어떻게 적용되는지 특정분야를 가지고 설명을 하도록 하겠습니다. 대표적인 분야로 자연어처리 분야를 예로 사용하겠습니다.
우리가 번역하고자하는 언어를 데이터로 사용해서 번역하고자 언어로 변역하는 시스템이 신경망 기계번역이라고 보시면 될 것 같습니다.
4. 기계번역에서의 어텐션 메커니즘
인코더-디코더 방식의 경우 인풋데이터를 특정 크기의 벡터 사이즈로 압축 후 디코더를 통해 원하는 출력값을 산출하게 된다. ( 특정 크기의 벡터 사이즈가 고정되는 이유는 특정 크기의 벡터 사이즈로 데이터를 압축해서 표현하기 위함. Encoder -Decoder에 관해서는 따로 자세히 설명할 예정 ) 여기서 고정된 크기의 벡터를 사용했을 때 보통 이 벡터의 사이즈가 사용된 데이터를 압축하는식으로 진행되기 때문에 데이터의 특징을 대표하는 feature이면서 동시에 데이터의 손실이 발생하게 된다. 이에 대해서 문제제기를 Neural Machine Translation By Jointly Learning To Align Translate논문에서 했으며, 이를 극복방안 중 하나로 Attention 기법을 제안하였다.
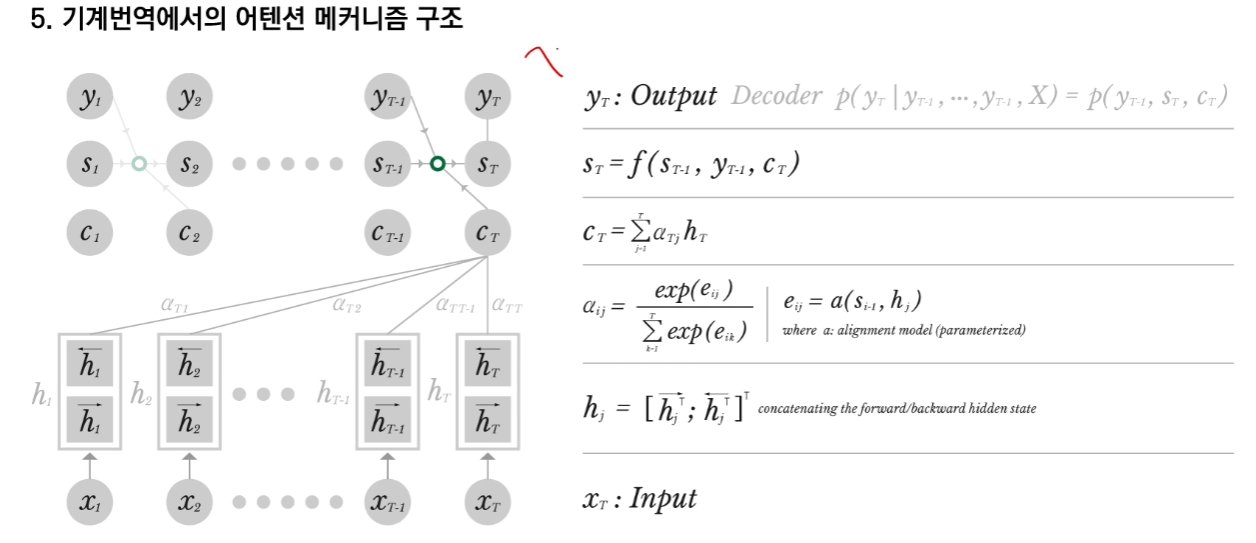
5. 기계번역에서의 어텐션 메커니즘 구조
메커니즘 구조에 대해서 좀 더 자세히 설명하자면 X_1 ~ X_T 까지의 입력 데이터값이 주어지게 되면 RNN의 구조를 통해서 Hidden state 값을 뽑아내게 되는데, Hidden state 값의 경우 정방향 RNN에서 나온 Hidden state 값과 역방향 RNN에서 나온 Hidden state 값을 concatenate 이어붙여서 사용합니다.
위의 그림을 보시면 y의 경우에는 최종 출력물이고 s의 경우는 linear mapping을 한 상태 마지막으로 c의 경우 중간 값이라고 기억하시면 됩니다.
( 위의 구조 연산은 따로 좀 더 자세히 설명을 진행하도록 하겠습니다. Vision만하다보니 어텐션은 어렵네요...)
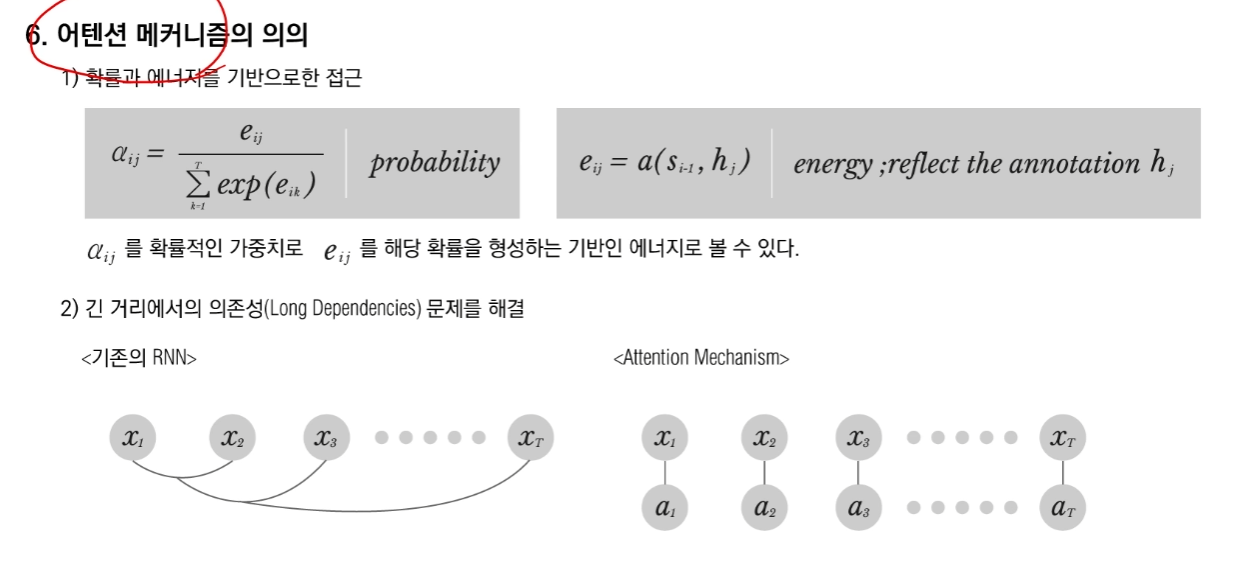
6. 어텐션 메커니즘의 의의
위의 수식을 보게 되면 어텐션을 사용하게 됐을 때, Softmax의 형태를 취하고 있음을 알 수 있습니다. 즉, 이말은 0~1사의 값을 가진다고 볼 수 있는데 이는 수학적으로 확률로 해석할 수 있음을 의미합니다.
기존의 RNN의 경우 연쇄적인 반영을 통해서 feedback시스템이 구성이 되기 때문에 길이가 길어질 경우 dependency가 생길 수 있지만 Attention의 경우 각각의 x에 따른 h를 뽑아내게 되고 각각의 a값에 따른 가중치들이 반영이 되기 때문에 기존의 RNN에 비해서 길어질 경우에 발생하는 부분을 조금 해소할 수 있을것 입니다.